Введение
Многопоточный код в разработке - обычное дело. Стандартные библиотеки современных языков зачастую уже включают в себя готовые оптимизированные структуры данных, безопасные для работы в многопоточной среде. Но однажды настает час, когда готовых решений становится недостаточно и вам требуется написать и протестировать свое.
Скорее всего, разработчик захочет от новой структуры как минимум следующего: быть быстрой и быть потокобезопасной. Так вышло, что эти требования часто противоречат друг другу. Например, можно каждую операцию структуры обернуть в критическую секцию, но тогда никакой выгоды от многопоточного исполнения не получится. Поэтому разработчики стремятся свести к минимуму блокирующиеся области кода или избавиться от них совсем (как это сделано в Lock-free структурах). Чем больше оптимизаций -- тем сложнее алгоритм.
Предположим, вы сформулировали на уровне идеи принципы и методы вашей структуры, которая кажется вам быстрой и безопасной; описанные формальными средствами алгоритмы кажутся вам корректными. Теперь настало время написать задуманную структуру уже на настоящем языке, используя настоящие библиотеки, а заодно добавить в резализацию настоящие баги. Идея может быть бесконечно хороша, но какой в этом толк, если прод лежит?
Lincheck - это фреймворк для языка Kotlin (кстати, изначально написанный на Java), который предоставляет инструментарий для тестирования структур данных на линеаризуемость (ну или если менее точно -- на потокобезопасность) и некоторые другие контракты.
Линеаризуемость
Линеаризуемость - это свойство программы, при котором результат любого параллельного выполнения операций эквивалентен некоторому последовательному выполнению. Это значит, что каждая операция, выполняющаяся в некотором потоке, является атомарной для всех остальных потоков - они не могут получить доступ к промежуточным результатам ее исполнения.
Для всех сценариев многопоточного исполнения программы можно построить граф состояний - представление всех возможных сценариев последовательного исполнения операций в многопоточной среде с информацией о состоянии системы до и после выполнения этих операций. Если реализованный алгоритм в одном из тестов приводит систему в формально невозможное состояние (которого нет в графе) - то этот алгоритм некорректен. Очень грубо говоря, именно так Lincheck проверяет структуры на линеаризуемость.
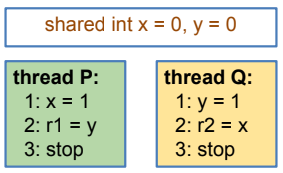
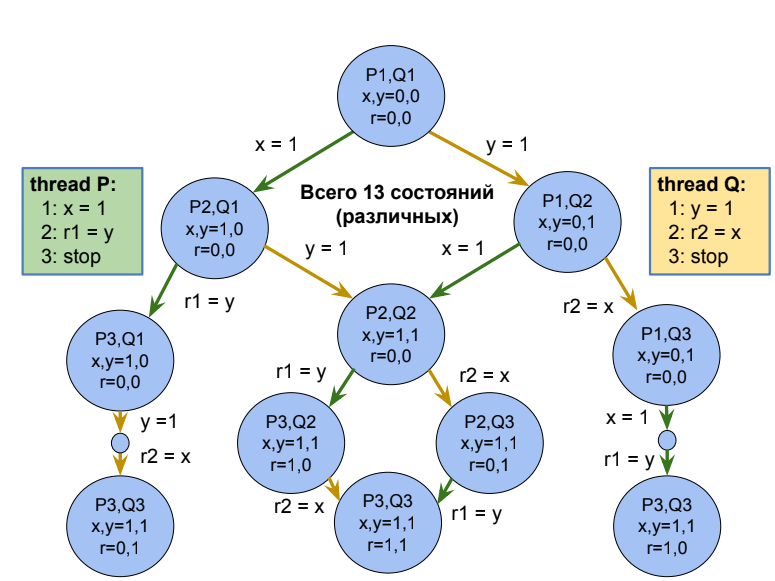
Первый тест
В качестве первого теста напишем простой счетчик с двумя операциями: прибавить некоторое значение (возвращает состояние счетчика после сложения) и обычный геттер, который просто возвращает состояние и ничего не прибавляет.
Объявим интерфейс и напишем наивную реализацию. Знакомясь с понятием линеаризуемости, мы конечно же сразу вспомнили про сущестование кэшей в слабой модели памяти, поэтому над переменной-счетчиком поставили аннотацию @Volatile, чтобы все точно работало!
interface Counter {
fun addAndGet(v: Int): Int
fun get(): Int
}
class NaiveCounter: Counter {
@Volatile
private var value = 0
override fun addAndGet(v: Int): Int {
value += v
return value
}
override fun get() = value
}
Перед тем как писать тесты, добавим нужные зависимости. Собирать будем в Gradle, тестировать в JUnit 5
testImplementation("org.junit.jupiter:junit-jupiter:5.9.0")
testImplementation("org.jetbrains.kotlinx:lincheck:2.14.1")
Напишем вспомогательный интерфейс и дополним его реализацией с нашим наивным счетчиком
internal interface CounterTest {
val counter: Counter
@Operation
fun addAndGet(v: Int) = counter.addAndGet(v)
@Operation
fun get() = counter.get()
}
internal class NaiveCounterTest: CounterTest {
override val counter = NaiveCounter()
}
Подход интрефейс-реализация может показаться несколько странным и избыточным. Так и есть, но я сделал это намеренно и позже станет понятно зачем. Пока что обратим внимание на аннотацию @Operation. Она нужна для того, чтобы объяснить линчеку из каких операций необходимо сгенерировать тест-кейсы - ничего сложного. Если быть достаточно внимательным, то можно задаться вопросом - как линчек "придумает" параметры, с которыми будет вызывать метод addAndGet? К счастью, для примитивных типов линчек умеет генерировать параметры самостоятельно. Добиться некоторого желаемого поведения можно конфигурируя стандартные генераторы. Также можно написать и свой.
Написанный интерфейс - лишь часть теста. Теперь обратимся к JUnit, чтобы дописать тест до конца.
internal class CountersTest {
@Test
fun naiveTest() = StressOptions().check(NaiveCounterTest::class)
}
Да, вот так просто! StressOptions - одна из стратегий тестирования. Мы всего лишь создаем ее инстанс (который можно предварительно сконфигурировать), а затем просто вызываем метод check, передавая тестируемый класс.
Самое время объяснить мой странный финт с интерфейсом тест-класса. Ведь можно было создать единственный класс и в конструктор передавать инстанс нужного счетчика. К сожалению, так нельзя. Линчекер сам создает инстанс тестируемого класса через рефлексию, и нет (во всяком случае пока) механизма, чтобы указать параметры конструктора для класса. Такой подход связан с внутренней кухней фреймворка, которую я коротко затрону, но позже.
Анализ результатов и конфигурирование
Давайте наконец запустим тест и убедимся, что написали все правильно.
= Invalid execution results =
Parallel part:
| addAndGet(6): 6 | addAndGet(-8): -8 |
Какая жалость, мы написали небезопасный код! Чтобы понять, что произошло, давайте внимательнее разберем вывод линчекера. Начнем с надписи "Parallel part". Тесты в линчекере проходят в три фазы: начальная, основная и завершающая. В нашем тесте присутствует только основная - это часть, где непосредственно выполняется тестирование в многопоточной среде, это и есть "Parallel part". Начальная фаза выполняется последовательно и нужна в основном для заполнения структуры некоторыми начальными данными. Завершающая фаза нужна, чтобы, например, освободить какие-то ресурсы или привести структуру в корректное состояние.
Для наглядности давайте отключим упрощение ошибки:
Упрощение ошибки - это очень полезный механизм в линчекере. При возникновении ошибки он удаляет операции из неудачного сценария до тех пор, пока сценарий остается неудачным. Это значительно упрощает поиск небезопасных частей в коде.
@Test
fun naiveTest() = StressOptions()
.minimizeFailedScenario(false)
.check(NaiveCounterTest::class)
= Invalid execution results =
Init part:
[get(): 0, get(): 0, addAndGet(2): 2, get(): 2, get(): 2]
Parallel part:
| addAndGet(6): 8 | get(): 2 |
| addAndGet(-6): -8 [1,3] | get(): 2 |
| get(): -8 [2,4] | addAndGet(-8): -6 |
| addAndGet(1): -7 [3,5] | addAndGet(4): -2 |
| get(): -7 [4,5] | get(): -8 |
Post part:
[get(): -7, get(): -7, addAndGet(-8): -15, get(): -15, addAndGet(5): -10]
На самом деле по дефолту в каждой части выполняется по 5 случайных действий. Числом операций можно управлять с помощью конфигураций actorsBefore, actorsPerThread, actorsAfter. Если рандомные действия вас не устраивают, то можно написать свой сценарий на очень удобном DSL. В README репозитория написан исчерпывающий пример такого сценария, поэтому я не буду на нем останавливаться. Также упомяну о еще нескольких полезных параметрах конфигурации:
-
threads - количество потоков в параллельной части
-
iterations - количество различных сценариев, которые будут сгенерированы
Итак, наш счетчик не работает. В таком простом примере причины очевидны (особенно с упрощением ошибки), но что если мы имеем дело с очень сложной структурой и действительно не понимаем, где находится небезопасный код?
Стратегии тестирования
До этого момента мы говорили о стратегии StressOptions. В общем случае она хорошо себя показывает, но давайте подробнее разберемся как она работает. Эта стратегия генерирует <iterations> сценариев, в которых в каждом из <threads> потоков параллельно выполняется <actorsPerThread> операций. Между всеми операциями в каждом потоке расставляются задержки случайной величины, чтобы сымитировать конкурентную среду.
Обычно такого "вероятностного" подхода достаточно, чтобы обнаружить ошибку, но у него есть и ряд недостатков. Во-первых, такой непоследовательный подход может просто пропустить какой-то важный сценарий и не обнаружить ошибку, во-вторых, при таком подходе невозможно выяснить порядок конкурентого обращения к памяти, что затрудняет поиск уязвимостей.
У линчека есть решение этих проблем, и называется оно ModelCheckingOptions. Эта стратегия тестирования не полагается на случайность. Вместо этого она разбивает операции в тестовом сценарии на действия с памятью - чтение и запись (Важно: в этой стратегии используется модель памяти с последовательной согласованностью, это нужно запомнить, мы к этому еще вернёмся). Затем в арсенал возможных операций добавляется переключение между потоками, и из этих примитивов (чтение, запись, переключение) строится дерево операций.
Но мы все еще ограничены количеством операций (параметры тестирования одинаковы для обеих стратегий), чтобы не поймать OutOfMemory! Поэтому это дерево строится подходом, напоминающим поиск в ширину. То есть сначала строится дерево для всех сценариев исполнения, но только с одним переключением потока, причем алгоритм старается не заходить вглубь, а рассмотреть как можно больше принципиально разных сценариев, прежде чем упрется в сконфигурированный лимит; затем с двумя переключениями и тп. Такой подход не только увеличивает покрытие, но и находит ошибку при меньшем количестве операций. Также важно, что дерево строится лениво, то есть при обнаружении ошибки тестирование прекращается, дерево не достраивается.
Чтож, давайте искать ошибку в нашем счетчике:
@Test
fun naiveTest() = ModelCheckingOptions().check(NaiveCounterTest::class)
= Invalid execution results =
Parallel part:
| addAndGet(6): 6 | addAndGet(-8): -8 |
= The following interleaving leads to the error =
Parallel part trace:
| | addAndGet(-8) |
| | addAndGet(NaiveCounterTest@1,-8): -8 at NaiveCounterTest.addAndGet(CountersTest.kt:27) |
| | addAndGet(-8): -8 at CounterTest$DefaultImpls.addAndGet(CountersTest.kt:21) |
| | value.READ: 0 at NaiveCounter.addAndGet(Counters.kt:16) |
| | switch |
| addAndGet(6): 6 | |
| thread is finished | |
| | value.WRITE(-8) at NaiveCounter.addAndGet(Counters.kt:16) |
| | value.READ: -8 at NaiveCounter.addAndGet(Counters.kt:17) |
| | result: -8 |
| | thread is finished |
Теперь все очевидно! Операция += неатомарна. В ходе ее выполнения произошло переключение на другой поток, который "испортил" значение в нашей переменной, и по итогу мы записали поверх него. Ну или можно сказать, что первый поток "не увидел" наше значение. Тут как посмотреть :)
Давайте исправляться. Воспользуемся идиоматичной библиотекой для атомарных операций: kotlinx.atomicfu.
Напишем атомарный счетчик:
class AtomicCounter: Counter {
private val value = atomic(0)
override fun addAndGet(v: Int) = value.addAndGet(v)
override fun get() = value.value
}
И тесты:
internal class AtomicCounterTest : CounterTest {
override val counter = AtomicCounter()
}
@Test
fun atomicTest() = StressOptions().check(AtomicCounterTest::class)
На этот раз все хорошо!
Слабые модели памяти
Раз ModelCheckingOptions такой крутой, зачем нам StressOptions? К сожалению, у последовательного похода ModelCheckingOptions есть свой недостаток - он не может симулировать работу в слабой модели памяти. Давайте рассмотрим следующий пример:
internal class WeakModelRaceTest {
private var x1 = 0
private var y1 = 0
private var x2 = 0
private var y2 = 0
@Operation
fun x(): Int {
x1 = 1
y2 = y1
return y2
}
@Operation
fun y(): Int {
y1 = 1
x2 = x1
return x2
}
@Test
fun test() = StressOptions()
.actorsPerThread(1)
.threads(2)
.invocationsPerIteration(100_000)
.iterations(2000)
.check(this::class)
}
Думается, что никаких проблем многопоточного исполнения тут нет и возможны три исхода: (0;1), (1;0), (1;1). Однако во время стресс-теста выясняется, что программа выдает некий "невозможный" исход -- (0;0). Такой результат получается из-за буферов записи слабой модели памяти. Значения, присвоенные в начале каждой операции переменным x1 и y1 попадут в основную память не сразу. Потоки получают "несвежие" данные из общих ресурсов (а еще компилятор мог поменять инструкции местами). Добавьте аннотацию @Volatile и боль пройдет.
Стратегия ModelCheckingOptions не может находить подобные уязвимости, так как исполняет код в модели памяти с последовательной согласованностью.
Проверяем на корректность
Когда мы пишем сложную структуру данных (уж точно не счетчик), линчек ничего не знает о том, как она должна работать. Не совсем понятно как в таком случае проверять линеаризуемость - неизвестно какие результаты операций "правильные". Следующий код "очереди" линчек считает вполне корректным.
class ConcurrentQueueTest {
@Operation
fun add(v: Int): Unit { }
@Operation
fun poll(): Int? = 0
}
internal class QueueTest {
@Test
fun naiveTest() = StressOptions().check(ConcurrentQueueTest::class)
}
Давайте не дадим себя обмануть и определим последовательную спецификацию. Фактически нам нужно передать корректную, но не обязательно потокобезопасную реализацию тестируемой структуры данных.
class ConcurrentQueueSequential {
private val list = LinkedList<Int>()
fun add(v: Int) = list.add(v)
fun poll(): Int? = list.poll()
}
internal class QueueTest {
@Test
fun naiveTest() = StressOptions()
.sequentialSpecification(ConcurrentQueueSequential::class.java)
.check(ConcurrentQueueTest::class)
}
Мы создали класс ConcurrentQueueSequential с теме же методами, что и у ConcurrentQueueTest, а в качестве гаранта использовали обычный LinkedList. Немного меняем код QueueTest, запускаем, и наблюдаем LincheckAssertionError.
Давайте вместо нашей "поддельной" реализации воспользуемся ConcurrentLinkedQueue из java.util.concurrent.
class ConcurrentQueueTest {
private val queue = ConcurrentLinkedQueue<Int>()
@Operation
fun add(v: Int) = queue.add(v)
@Operation
fun poll(): Int? = queue.poll()
}
Запускам тест, ждем и - выдыхаем. Структура из стандартной библиотеки прошла тестирование - Какое облегчение!
Резюмируя - чтобы проверять поведение вашей конкурентой структуры, линчеку нужна последовательно корректная версия тестируемой структуры - по ней будут сверяться результаты каждой операции.
Чтож, на этом, пожалуй, и все. Конечно линчек умеет намного больше, чем представлено в этом коротком разборе (как минимум - проверять на другие контракты потокобезопасности). Но основные на мой взгляд возможности и подходы были рассмотрены. Удачи и поменьше вам ошибок в коде :)

