Возможно, что вы пришли сюда, потому что не очень хорошо понимаете что есть стек, что есть куча и для чего они нужны. Вообще, найти ответ на этот вопрос мы можете в одной из моих заметок, но, к сожалению, т.к. в ней всё описано в терминах архитектуры ЭВМ, появился некий порог вхождения, который многие 'чайники' не смогли преодолеть. Поэтому предлагаю попробовать рассмотреть эту же тему вновь.
Говорить буду в основном в контексте языка Java, но концепции эти не особо отличаются в других языках.
Обычно всё начинается с простого вопроса: "Что хранится в стеке, а что в куче?" . Неопытный Java-программист скажет вам: "В стеке хранятся примитивы, а в куче объекты.". Такой ответ, неправильный. Вопрос: Почему?
Во-первых, нужно понимать при рассмотрении этой проблемы, что и стек, и куча служат для хранения данных программы.
Давайте рассмотрим пример простой программы и определим какие вообще бывают данные в программе.
public class App {
public static void main(String[] args) {
System.out.print("Введите a:");
int a = Integer.parseInt(System.console().readLine());
System.out.print("Введите b:");
int b = Integer.parseInt(System.console().readLine());
System.out.println("a+b=" + pow(a,b));
}
public static Long pow(int base, int exponent) {
Long result = 1L;
for (int i = 0; i < exponent; i++) {
result *= base;
}
return result;
}
}
Программа выше читает с консоли числа a и b и возводит a в степень b. Что же в этой программе является данными? Очевидно, что данными являются переменные объявленные в программе. Окей у нас есть переменные a, b, result. Но как теперь понять что где хранится и что вообще такое стек и куча?
Для этого рассмотрим ещё одну важный термин - область видомости. У каждой переменной есть своя область видимости. При росте сложности программы возникает необходимость разбивать её на какие-то структурные единицы. Это позволяет уменьшить сложность программы. Также можно определить некоторые повторяющиеся блоки кода и использовать в разных местах программы.
В языках программирования для такой ситуации существуют именованные блоки кода, которые называют функциями/процедурами. Такие блоки выполняют некоторую логическую последовательность действий и могут работать с разными данными. В примере выше мы вынесли блок кода, отвечающий за возведение числа в какую-то степень в отдельную функцию. Для того, чтобы функции могли выполняться над разными данными существует понятие аргументов. Как видно из примера, объявленная функция pow должна получать на вход 2 целочисленных аргумента: первое значение будет использоваться функцией как основание, а второе как степень.
Теперь можно дополнить список того, что мы зовем данными в программе: a,b, result, base,exponent.
Вернёмся к понятию область видимости. У каждой перменной есть некоторая область внутри которой её видно. Плюс у каждой перменной есть своё время жизни. Надеюсь, понятно, что у каждой программы есть свой поток исполнения. Например в примере выше сначала считаются два значения, потом выполнится функция pow, а её результат после этого выведется на консоль. Переменные должны где-то храниться и когда они нужны должна быть возможность прочитать их значение или изменить. Очевидно, что хранится они должны в памяти компьютера (допустим в оперативной). И важно, чтобы когда переменная уже больше не будет нужна, то место которое она занимает освободилось, иначе в какой-то момент память у нас просто кончится. В нашем примере нужно
А теперь перейдем к рассмотрению такого понятия как стек. По сути под стеком подразумевается некоторый принцип хранения и обращения к данным. Хорошим примером стека можно назвать стопку тарелок. К ней будет применимо две операции, положить новую тарелку наверх стопки, либо же взять верхнюю тарелку, собственно этими двумя операциями и организуется принцип LIFO (Last In - First Out).

Какое отношение эта стопка имеет к нашему разговору? А вот, оказывается, что такой принцип очень удобно применять для того чтобы управлять временем жизни и видимости перменных.
Происходит это следующим образом: Как только программа начинает выполнять какую-то функцию, то под используемые в ней перменные выделяется место в стеке. Например при старте нашей программы в стеке будет выделено место под перменые args, a, b. По мере выполнения это функции ячейки в стеке будут заполняться какими-то значениями. В тот момент, когда программа дойдет до вызыова функции pow в стеке создастся место под переменные необходимые для этой функции. С некоторыми упрощениями стек будет выглядеть следующим образом:
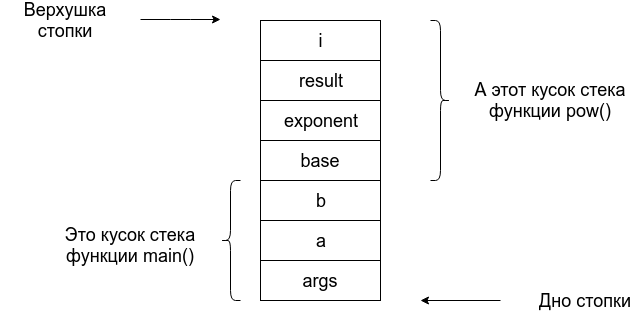
Как видно из примера, получается, что у каждой функции есть свой кусочек стека и когда фукнция обращается к переменным, то на самом деле за этими именами стоят какие-то места в его собственном кусочке стека (их обычно называют кадрами или фреймами).
Первое на что нужно обратить внимание - это то, что аргументы функции (base, exponent) являются отдельными местами в памяти. Может показаться, что раз в нашей программе мы передаем в функцию pow a и b, то внутри неё мы будем общаться с этими местами в стеке. Это мнение ошибочно, Код вызываемой функции (pow) не может менять переменные внешней функции (main), поэтому когда при исполнении программа доходит до строки с вызовом функции pow(a, b), значения, которые хранятся в соответствующих местах копируются в места выделенные под base и exponent. В момент, когда внутренняя функция заканчивает свою работу, то место в стеке используемое под неё очищается и может быть использовано дальше. Например для вызова следующей функции.
Посмотрим на это на примере:
public class App {
public static void main(String[] args){
int a = 3;
int b = 4;
int c = func1(a, b);
c++;
d = func2(c, a);
}
}
Здесь есть функция main(), в которой вызываются 2 функции func1 и func2.
Предположим, что в этот момент времени программа находится внутри func1 и что-то считает. В этот момент времени стек будет иметь следующий вид:
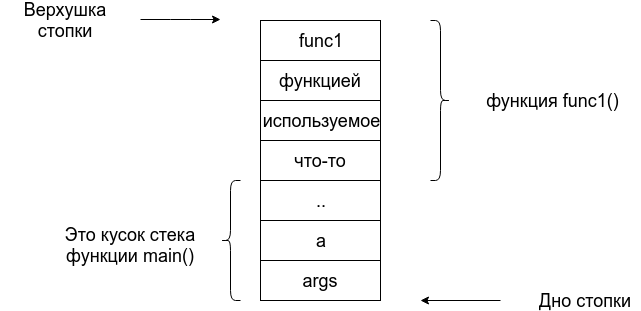
Очень важно, понимать, что в этот момент времени в стеке нет ничего, что имеет отношение к функции func2. В тот момент, когда мы войдем в func2 часть стека используемая под func1 будет стёрта, а на её месте будет func2.
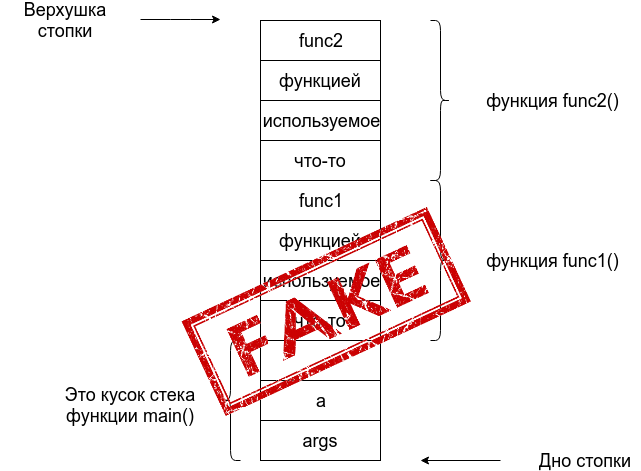
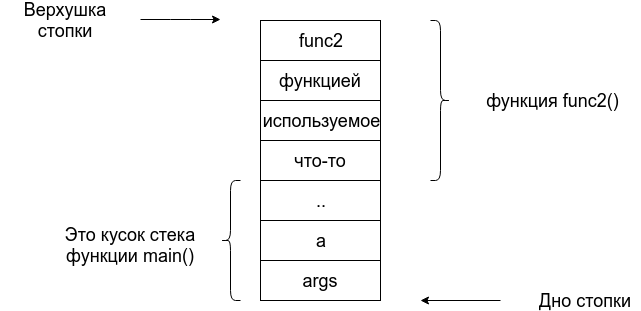
Изображение слево было бы верным, если бы func2 вызывался внутри func1. Вообще, когда происходит такая ситуация что у нас сейчас на стеке лежит N кадров, то это значит что сейчас мы находимся на глубине N, то есть выполнение сейчас находится на какой-то функции funcN, которая была вызвана другой функцией, а та ещё одной и ещё одной. Когда функция funcN выполнится, то её кадр удалится из стека и выполнение программы перейдет к тому, кто её вызывал. Так по ходу выполнения программы стек будет то углубляться и получать новые кадры, то раскручиваться назад и удалять кадры.
Подытожим историю со стеком. В стеке хранятся данные, относящиеся к контексту функций, которые на этот момент времени выполняются. К таким данным относятся локальные переменные функции (то, что объявлено в её теле), аргументы функции, адрес возврата и возможно возвращаемое значение (последние два удастся понять, если прочитать мою прошлую статью на эту тему).
А зачем нужна куча (heap)?
Давайте представим ситуацию, когда мы обрабатываем не просто числа или какие-то другие простые типы данных, а некоторые структуры. Например мы определили, что есть структура человек и она состоит из строки, описывающей имя человека и числа, описывающего его возраст. Получается, что когда нам нужно передать в функцию информацию о каком-то конкретном человеке, то нам нужно скопировать уже 2 значения. Вообще это похоже на то, как в примере выше копировались значения переменных a и b в аргументы функции. Но иногда возникает такая ситуация, когда необходимо копировать достаточно много данных и если делать это достаточно часто, то будет много накладных расходов как по времени на это, так и по используемой памяти на хранение множество копий.
Хотелось бы сделать так, чтобы какой-то функции можно было бы сказать, что мы передаем ей не само значение, а адрес где оно лежит. При такой схеме мы позволим какой-то функции func1 влезть в данные функции func2. Плюс сам стек не предоставляет таких операций, чтобы мы могли получить доступ к опеределенному месту в нем. Ещё одна проблема, которая у нас возникает - то, что если мы хотим создать нашу экземпляр нашей структуры где-то во внутренней функции и передать ссылку на это место наверх праотцам, то это будет невозможно, ибо в момент выхода данные этой функции будут уничтожены.
Для решения этих проблем было предложено сделать отдельную область памяти и назвать её кучей (heap). Куча будет хранить какие-то долгоживущие объекты. Например нашу информацию о людях или о котиках.
Теперь давайте представим, что у нас есть такой код на Java:
class Cat {
String name;
int age;
}
class App {
public static void main(String[] args) {
int number = 4;
String vasya = "Барсик"; //Внешность обманчива
Cat myCat = new Cat(vasya, number);
}
}
В этом коде мы объявили некоторый класс (структуру), которая описывает кота и содержит информацию о его возрасте и имени. В функции main мы создали несколько переменных, в том числе создали нового кота.
Исходя из того, что обсуждалось ранее не трудно догадаться, что new Cat - создание объекта, который будет храниться в куче. В этом месте нужно понять, что объекты в куче создаются в момент работы программы, тогда как это понадобится. И созданный объект в памяти будет лежать по какому-то адресу памяти. И адрес этот надо где-то хранить. Ведь мы же должны будем как-то передать потом информацию где в куче искать кота другим функциям. Адрес того места где лежит наш объект будет лежать в стеке. Если конкретно, то он будет скрываться под переменной с названием myCat. Она будет хранить адрес нашего кота, который лежит в куче. Выглядеть это будет примерно вот так.

Как видно на картинке, стек хранит адрес объекта, который лежит в куче. Теперь если нам нужно будет передать нашего кота в какую-то другую функцию, то мы просто скопируем его адрес в стек другой функции. Получается, что какие-то переменные хранят адрес, а какие-то само значение. По этой причине в Java типы данных переменных разделяют на два типа. Ссылочные типы данных и примитивные. Примитивные типы хранят само значение, а ссылочные - адрес на место в кучи, где лежит объект. Для полноты картины, давайте представим, что у нашего кота появилась дополнительная информация о его владельце, которая представлена информацией об имени и кол-ве денег у него. Тогда куча будет выглядеть следующим образом.
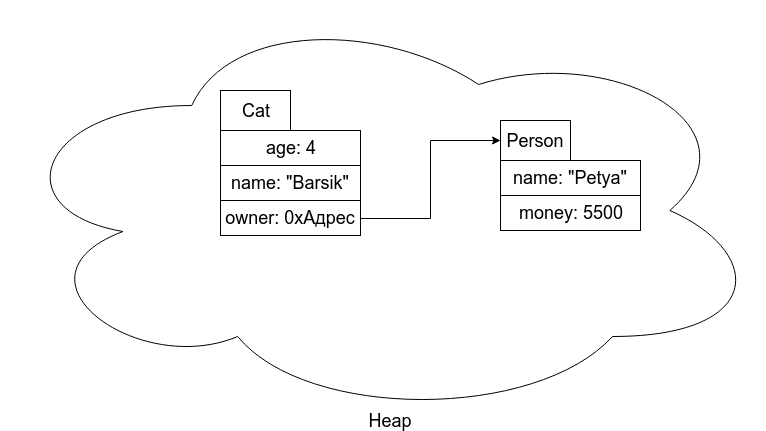
Этот пример даёт понять важную вещь - адрес на объект не всегда хранится в стеке. В нашем примере владелец - часть информации о коте и если кот хранится в куче, то и ссылка на его владельца хранится там же. Но при этом так как Человек - ссылочный тип данных, то он тоже хранится в куче, а у кота есть ссылка на него. Ошибочно считать, то все данные о человеке будут находиться в том же кусочке где и данные кота. Также неверно считать, что если у нас переменная имеет примитивный тип данных, то она лежит в стеке. Возраст является частью кота, поэтому он находится там же где и информация о коте. Но при этом там лежит само значение 4, а не какой-то адрес, который указывает на место где записано 4.
Из всего сказанного ранее следует, что в стеке хранится контекст исполняемых функций, а именно их локальные переменные, переданные в них аргументы, а также адрес возврата и возвращаемое значение. В зависимости от того какой тип имеют эти переменные (ссылочный или примитивный) в стеке могут лежать либо сами значения, либо адрес на место в куче. В куче же хранятся все объекты (которые являются ссылочными типами данных). Если объект содержит примитив, то внутри блока памяти отведенного под этот объект хранится само значение (в нашем примере 4), если же объект содержит ссылочный тип данных, то внутри него хранится адрес на другое место в куче, которое содержит информацию об этом объекте.
Надеюсь, что после прочтения этой статьи у вас возникло понимание того, что есть стек, а что есть куча.
На этом, пожалуй, откланяюсь.

