Введение
Дедупликация является актуальной технологией находящей всё большее применение в области резервного копирования и восстановления данных.
Сегодня большинство систем хранения корпоративного уровня поддерживают данную технологию. Среди компаний производителей таких систем лидеры мирового уровня в данной области EMC, IBM, NetApp, HP, Oracle, Quantum.
На сегодняшний день большинство существующих корпоративных систем резервного копирования/восстановления данных обладают собственной реализацией технологии дедупликации данных, ввиду наиболее эффективного применения данной технологии именно в области резервного копирования данных по причине наличия большой избыточности в наборах данных резервных копий.
Следует отметить, что в крупных инфраструктурах, имеющих террабайты продуктивных данных, применение дедупликации в резервном копировании позволяет существенно сократить затраты на приобретение и поддержку информационных систем, за счет сокращения потребностей в пространстве для хранения резервных копий, так как все технические характеристики системы, а также стоимость внедрения и владения существенно зависят от применяемых технологий хранения и резервного копирования.
В случае наличия распределенной системы резервного копирования между различными площадками инфраструктуры соединенных через глобальную компьютерную сеть (WAN), обладающую ограниченной, как правило не достаточно высокой пропускной способностью, применение дедупликации позволяет сократить время передачи/репликации данных резервных копий между площадками, позволяя в определенных случаях осуществить размещение необходимых данных в территориально удаленном месте в отведенное под данную задачу время. На сегодняшний день подобная потребность растет с развитием и уменьшением стоимости сервиса типа «облачное хранилище данных» cloud storage, позволяющее защитить данные в случае физического уничтожения серверной в случае стихийных, технологических бедствий или изъятия оборудования и устройств хранения проверяющими органами.
Обзор существующих решений из области резервного копирования
Далее представлен список состоящий из мировых лидеров систем резервного копирования с кратким описанием примененной технологии дедупликации:
-
Symantec Backup Exec* – хешевая дедупликация реализованная в виде хранилища дедупликации (deduplication storage) на медиа сервере (media server) в программном продукте, с фиксированным размером блока от 32 КБ до 1МБ, хранящая метаданные в СУБД PostgreSQL.
-
Symantec NetBackup* – хешевая дедупликация использующая алгоритм хеширования MD5, реализованная в виде хранилища на медиа сервере в программном продукте, с фиксированным размером блока от 32 КБ до 16МБ хранящая метаданные в СУБД PostgreSQL
-
Veeam Backup & Replication* – хешевая дедупликация реализованная в рамках отдельной задачи резервного копирования с фиксированным размером блока 8 КБ.
-
Acronis Backup Advanced* - хешевая дедупликация с использованием двух алгоритмов хеширования (быстрое и полное) для сокращения объема метаданных.
-
EMC Avamar* - программно-аппаратный комплекс обеспечивающий хешевую дедупликацию с блоком данных переменной длины от 1 до 64 КБ.
-
HP Data Protector* – дедупликация имеет две реализации: хешевую(
HP Dynamic Deduplication) с размером блока в 4 КБ использующую алгоритм хеширования SHA-1 вместе с контрольной суммой CRC, а так же объектную (
HP Accelerated Deduplication) обеспечивающую устранение избыточности путем поиска подобных объектов в наборах данных(Object-level differencing). .
-
IBM Tivoli Storage Manager* – хешевая дедупликация использующая алгоритмы хеширования SHA-1 и MD-5, реализованная на уровне дискового хранилища (пула) с размером блока равным размеру блока на пуле, с поддержкой одним экземпляром до 400 ТБ данных, хранящая метаданные во внутренней СУБД.
Дедупликация и компрессия
Дедупликация позволяет сократить время выполнения сжатия данных используя последовательную обработку данных дедупликацией, сокращая количество избыточных данных, и производя компрессию над уже дедуплицированными данными. При компрессии в общем виде представляет из себя изменение кодирования внутри блоков данных определенной длины. При сокращении количества блоков (в случае первоначальной обработки данных дедупликацией) время потраченное на компрессию будет меньше на время обработки для сокращенных блоков, а общий коэффициент сокращения объема данных будет так же меньше, чем при использовании одной компрессии, за счет сокращения количества сжатых объектов на выходе. Оценить параметры по времени можно зная среднюю скорость работы системы компрессии с определенным алгоритмом на целевой системе, среднюю скорость дедупликации данных, оценочный коэффициент дедупликации используемого для сокращения набора данных.
Применение последовательности из дедупликации и сжатия данных реализовано по умолчанию в продуктах
Quantum DXI, В качестве примера на рисунке приведено изображение из управляющего интерфейса продукта
Quantum DXiV1000 использующегося в качестве системы хранения резервных данных 4 баз данных MS SQL и дифференциальных резервных копий 4 однородных систем на платформе Microsoft Windows Server 2008R2 и одной системы на платформе Linux (дистрибутив openSuse 12.3).
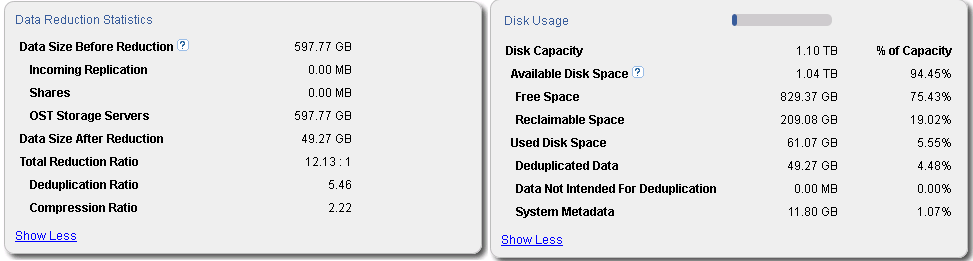
Как видно из информации из управляющего интерфейса, общее сокращение объема после обработки сокращено в 12 раз (Total Reduction Ratio в блоке Data Reduction Statistics), при этом сокращение объема более чем в 5 раз приходится именно на обработку дедупликацией (Deduplication Ratio в блоке Data Reduction Statistics), с последующем сокращением дедуплицированных данных алгоритмом компрессии в более 2 раз(Compression Ratio) в блоке Data Reduction Statistics. Помимо самих данных требуется хранить метаданные, обеспечивая целостность данных, которые на данном наборе хранения занимают 11,8 ГБ (System Metadata в блоке Disk Usage), большей частью которых являются метаданные используемые при дедупликации данных.
Суммируя объем обработанных данных с объемом метаданных общий объем необходимый для хранения резервных копий данных сокращается в 10 раз, что является наглядным показателем эффективности применения технологии дедупликации данных.
Ленточные накопители
Использование дедупликации данных для хранения информации на ленточных носителях в определенных случаях позволяет переогранизовать политики хранения резервных копий и сократить количество задействованных ленточных накопителей для хранения резервных копий за определенный период, что является важным преимуществом важным при регулярном перенесении ленточных накопителей на другую площадку для защиты и сохранения данных от стихийных, технологических бедствий или изъятия оборудования и устройств хранения проверяющими органами. При записи дедуплицированных данных на ленточный накопитель так же происходит компрессия регламентированная стандартами LTO в виде алгоритмов
ADLC, для накопителей до поколения LTO-5 включительно, или LTO-DC, для накопителей поколения LTO-6.
По данным исследования агенства Gartner
«Organizations Leverage Hybrid Backup and Recovery» крупные компании для резервного копирования используют комбинированный подход при использовании дисковых хранилищ и ленточных накопителей.Данная стратегия хранения резервных копий позволяет увеличить скорость процесса и уменьшить время резервного копирования в отношении наиболее актуальных данных и критической информации, а так же снизить стоимость владения инфраструктурой резервного копирования при долговременном хранении информации. Использование дедупликации позволяет оптимизировать занимаемые объемы резервных копий данных, что позволяет эффективно производить архивирование данных с использованием меньшего количества ленточных накопителей.
Заключение
Дедупликация является актуальной технологией, находящей применение всё в большем количестве предприятий. Постоянное развитие и интеграция решений дедупликации данных производителями систем хранения данных и решений резервного копирования подтверждают будущее за данной технологией, позволяющей оптимизировать и сократить затраты на стоимость внедрения и владения системы хранения резервных копий, а так же сократить время передачи информации при репликации резервных копий данных между территориально распределенными площадками.

