После ознакомления с предыдущей статьёй. внимательный читатель мог уже догадаться, что галочка Nested Paging в virtual box'е разрешает использовать аппаратную поддержку SLAT, что может существенно снизить накладные расходы на виртуализацию. И действительно, малого того, что раньше гипервизор должен был держать отдельный набор теневых таблиц для каждого процесса каждой гостевой ОС (а занимать они могут довольно много места), дак еще в придачу к этому гипервизор прерывал работу виртуальной машины каждый раз, когда гостевая ОС обновляла эти таблицы, чтобы синхронизировать свои теневые таблицы. Теперь же гипервизор не вмешивается в работу гостевой ОС с таблицами страниц, а просто поддерживает свой набор таблиц (nPT) для каждой ВМ для преобразования физического гостевого адреса (GPA) в машинный адрес (SPA). Аппаратура (блок MMU) уже сама ходит по всем этим таблицам, если необходимого адреса нет в TLB кэше. У Intel эта технология называется EPT, а у AMD - RVI. Прирост производительности может составлять более 30%.
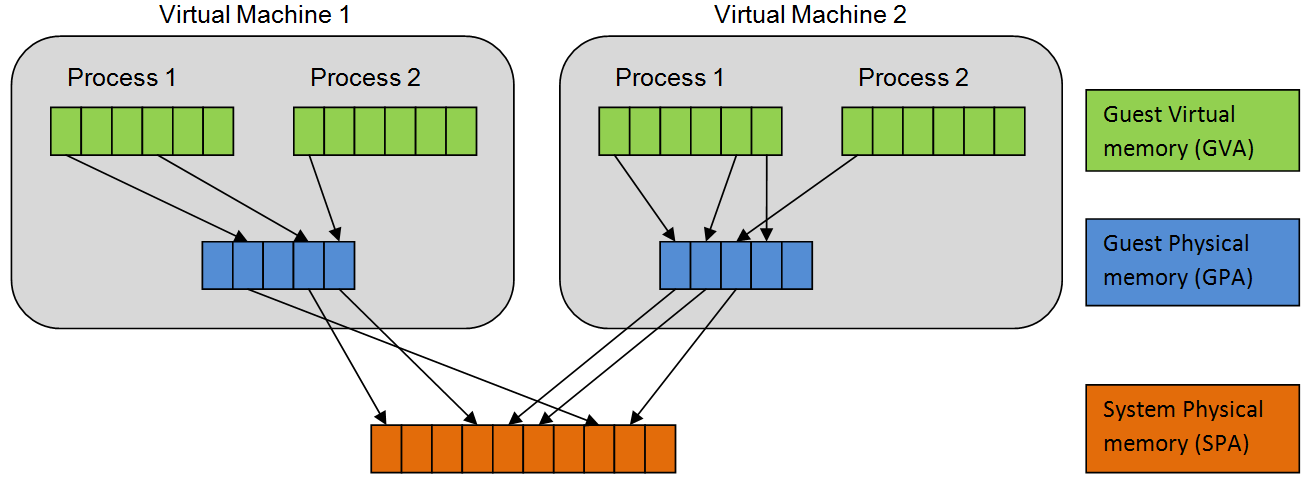
Однако у такого подхода имеются и не столь очевидные последствия. Но чтобы их понять, необходимо чуть подробнее рассмотреть структуру таблицы страниц. Начнём, пожалуй, с невиртуализированного случая.
Наиболее просто трансляция адреса в x86 архитектуре выглядит в случае 32-битного адреса и размера страницы 4MiB.
Аппаратный регистр CR3 содержит физический адрес начала таблицы страниц. Номер виртуальной страницы (старшие 10 бит виртуального адреса) используются в качестве индекса в этой таблице, и из неё выбирается соответствующий адрес физической страницы.
Если бы такая же схема использовалась для 64-битного адреса и 4KiB страниц, то таблица страниц должна была бы вместить 2^52 записей и занимать over 32PiB. Поэтому в данном случае применяется 4-х уровневые таблицы:
Запись в каждой таблице содержит адрес начала таблицы более низкого уровня, а соответствующий кусочек номера страницы является индексом. Последняя таблица (PT) содержит адрес физической страницы. Это позволяет выделять память под всю эту шляпу по мере того, как приложение будет запрашивать память у ОС.
Текущие спецификации архитекутры x86-64 ограничивают виртуальный адрес 48-ю битами, а физический - 52-мя битами. Поэтому верхние 16 бит виртуального адреса не используются.
Если запись о запрашиваемой странице отсутствует в TLB-кэше, то вместо одного обращения в память за данными, потребуется 5 (4 обращения для трансляции физического адреса + 1 обращение уже по делу). На самом деле есть еще куча разных кэшей, поэтому обращений в память может быть от 2 до 5.
А теперь виртуализируемся: принципиально, адрес сначала транслируется из виртуального в гостевой физический (GVA -> GPA), а потом в машинный (GPA -> SPA). Первым преобразованием рулит гостевая ОС, а вторым - гипервизор. У обоих свой регистр CR3 (gCR3 и nCR3). Гостевая ОС ровно так же, как и раньше, управляет своими таблицами страниц, не подозревая о наличии гипервизора. А гипервизор в это и не вмешивается. А теперь вопрос: в каком пространстве находятся адреса, содержащиеся в таблицах гостевой ОС? Правильно, в гостевом физическом (GPA), т.е. всё ещё немножко в виртуальном.
TLB в данном случае кэширует сразу преобразование из "самого виртуального" (GVA) в "самый физический" адрес (SPA).
Допустим нам не повезло и TLB-кэш пуст. Для доступа к странице сначала мы должны понять, куда указывает gCR3 и сделать 4 обращения в память для трансляции этого адреса. Лазить понятно дело надо в nPML4, nPDP, nPD, nPT. Далее +1 обращение в сам gPML4. Теперь должны понять, куда указывает gPML4E. Опять +4 обращения для трансляции GPA->SPA. И в самом неблагоприятном случае так будет с каждым уровнем таблиц гостевой ОС. Хитрая арифметика говорит, что, в случае тотального непопадания во все кэши, одно обращение в память выльется в 25. Я бы рискнул назвать данный overhead существенным. Борьба с ним ведётся по двум фронтам:
-
уменьшение стоимости TLB-промаха. Для этого был добавлен еще один тип страничного кэша - nTLB. Как можно догадаться, nTLB кэширует то, чем заведует гипервизор, т.е. трансляции GPA->SPA.
-
уменьшение количества TLB-промахов. Самая большая засада возникает при смене активной виртуальной машины (смене контекста на стороне гипервизора). При этом, как принято в x86 архитектуре, TLB должен полностью инвалидироваться, а его повторное наполнение, как мы выяснили, может быть неприятным процессом. Чтобы этого не делать, записи в TLB дополнительно помечаются специальным тегом (ACID у AMD, и VPID у Intel). Гипервизор выдает каждой виртуальной машине свой уникальный тэг. При трансляции адреса, запись из TLB используется, только если её тэг совпадает с текущим активным тэгом. Это позволяет держать в TLB записи, относящиеся к разным ВМ, и не инвалидировать их при переключении. Понятно дело, что количество записей в TLB, пришлось существенно увеличить, чтобы оставить вменяемый cache hit ratio. К слову сказать, у Intel'овских процессоров имеется похожая фишка под названием PCID, чтобы не сбрасывать TLB при смене контекста процесса.
Кроме этого, использование страниц большого размера также положительно сказывается на эффективности TLB. Во-первых, одна запись в TLB покрывает бОльший объём памяти. А, во-вторых, уменьшается количество таблиц и, соответственно, количество обращений в память, необходимых для трансляции адреса в случае TLB-промаха.
На реальных нагрузках аппаратная поддержка SLAT даёт очень хороший результат:
-
+30% на Citrix Server Test Kit
-
до +10% на SQL Server Database Hammer
Но, горячо любимая в наших кругах

, Java способна творить чудеса и может легко просесть на маленьких страницах (тут аппаратный SLAT - это RVI):
Собственно сами тесты от VMware:
Для тех, кто любит чтиво пожёстче и хочет узнать какие еще в аппаратуре присутствуют страничные кэши, я посоветую два манускрипта общим объёмом 1998 страниц:
Смотреть в основном сюда:
-
5 Page Translation and Protection
-
15 Secure Virtual Machine
-
15.16 TLB Control
-
15.25 Nested Paging
Интересное тут:
-
CHAPTER 4 PAGING
-
4.10 CACHING TRANSLATION INFORMATION
-
4.11 INTERACTIONS WITH VIRTUAL-MACHINE EXTENSIONS (VMX)
-
CHAPTER 28 VMX SUPPORT FOR ADDRESS TRANSLATION
