Часть 1. Платформа
Часть 2. Архитектура и библиотека ядра
Часть 3. Ключевые подсистемы ядра
В последней статье серии хотелось бы поговорить о ключевых подсистемах моего микроядра: диспетчере и планировщике потоков, менеджере памяти, системных вызовах и IPC (межпроцессной коммуникации).
Отложенные прерывания и таймер ядра
Операционные системы представляют из себя системное программное обеспечение и их задача - не решение конечной пользовательской задачи с использованием максимально доступных ресурсов, а обслуживание внешних запросов (от пользовательских потоков и аппаратуры) за максимально короткое время. Поэтому и одна из используемых парадигм при разработке ядра ОС - событийно-ориентированная. С другой стороны, многозадачная ОС (а тем более, ОСРВ) вынуждена сама контролировать время выполнения тех или иных задач (например в вытесняющей многозадачности - прерывать выполнение потока по истечении временного отрезка (time-slice), выделенного ему). В этом отношении ОС можно назвать управляемыми временем (time-driven).
За обработку событий отвечают в первую очередь обработчики прерываний. Однако крайне нежелательно размещать большое количество кода в таком обработчике: находясь на высоком уровне прерывания мы не можем передать управление другому потоку, поэтому была придумана концепция "нижних половин", которая реализована в L4Xpresso как softirq (см файл kernel/src/softirq.c). Рассмотрим подробнее ее на примере системного вызова.
1. Приложение совершает системный вызов посредством инструкции SVC (SuperVisor Call)
2. Срабатывает обработчик прерывания __svc_handler (kernel/src/syscall.c). Все что он делает - это сохраняет значение текущего потока в указателе caller (чуть раньше с помощью макроса irq_save был сохранен контекст, содержащий также и аргументы системного вызова). Он с помощью вызова softirq_schedule(SYSCALL_SOFTIRQ) планирует обработчик нижней половины syscall_handler.
3. Во время возврата из прерывания происходит попытка переключения контекста и выбирается поток ядра, отвечающий за обработку нижних половин.
4. Управление передается потоку ядра. Он вызывает функцию softirq_execute, которая проверяет флаги всех нижних половин и в свою очередь вызывает syscall_handler
5. Если все нижние половины были обработаны, управление будет передано другому потоку.
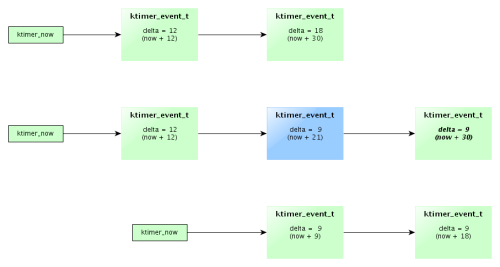
Привязку ко времени обеспечивает модуль ktimer (файл kernel/src/ktimer.c). Он использует в качестве аппаратного таймера системный таймер микроконтроллера SysTick, который генерирует прерывание с частотой, заданной константой CONFIG_KTIMER_HEARTBEAT. Сами события представляют из себя односвязный список структур ktimer_event_t. Переменная ktimer_now содержит номер последнего тика, функция ktimer_clock() возвращает соответствующее время в наносекундах (отдельно встает вопрос о монотонности такого времени), переменная ktimer_delta содержит количество тиков до ближайшего события и всякий раз при срабатывании таймера она уменьшается, а когда доходит до нуля, срабатывает нижняя половина ktimer_event_handler, которая обрабатывает список событий, привязанных к данному моменту времени.
Вычисляются такие привязки исходя из разности delta между событиями: пусть мы хотим запланировать событие, которое должно произойти 21 тик спустя его планирования и у нас есть события, привязанные ко времени +12 и +30). Для этого мы должны пересчитать разность времени как для нового события, так и для всех событий, которые должны случиться после него (это делается с помощью функции ktimer_event_recalc), как показано на рисунке.
Диспетчер потоков
Теперь можно поговорить о потоках. В отличие от классической модели Unix (процесс = N потоков + единое адресное пространство), в L4 используется более гибкая концепция, позволяющая создавать любое количество потоков, адресных пространств и отображать области памяти между ними. Также как и в случае KIP, в L4 предусмотрена специальная структура: User Thread Control Block размером в 128 байт (в L4Xpresso) и отображенная в пространство потока. Она содержит в частности так называемые Thread Control Registers (TCRs). Код управления потоками находится в kernel/src/thread.c
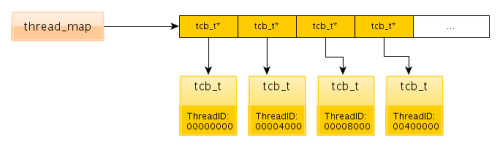
Для определения, какие же потоки используют общее адресное пространство им присваивается два идентификатора: global thread id, состоящих из 18 бит собственно номера потока и 14 бит, зарезервированных под номер версии и local thread id, содержащий в старших 26 битах номер потока в пределах одного адресного пространства. Для преобразования l4_thread_t в globalid предусмотрены макросы GLOBALID_TO_TID и TID_TO_GLOBALID. Управляющие структуры потоков в L4Xpresso - tcb_t (внутри ядра) и utcb_t (UTCB). Из-за того, что в Cortex-M3 отсутствует виртуальная память, зарезервировать ее под большой массив управляющих блоков tcb_t не представляется возможным (в L4Ka::Pistachio выходит что-то порядка 1 Мб). Вместо этого мы используем промежуточный массив указателей thread_map, который всегда отсортирован (что позволяет использовать бинарный поиск, что выгодно для операций IPC). Управляется он с помощью функций thread_map_search и thread_map_insert.
Указатель current содержит текущий исполняемый поток. Тогда по окончании обработки любого прерывания вызывается функция диспетчера schedule (kernel/src/sched.c), которая выбирает следующий поток на исполнение. При этом диспетчер имеет несколько слотов, и последовательно обходит их, пытаясь выбрать поток из наиболее приоритетного слота. Порядок потоков в слотах таков:
-
SSI_SOFTIRQ - Отложенные прерывания softirq
-
SSI_INTR_THREAD - Потоки пользователя, обслуживащие прерывания
-
SSI_ROOT_THREAD - Корневой поток пользователя
-
SSI_IPC_THREAD - Потоки пользователя, учавствующие в межпроцессной коммуникации
-
SSI_NORMAL_THREAD - Все остальные потоки пользователя
-
SSI_IDLE
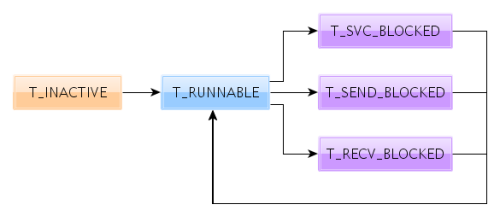
Планирование в L4Xpresso осуществляется с помощью системного вызова Schedule, однако эта часть функционала пока не реализована. Кроме того, как и в любой операционной системе, поток обладает состоянием, но в L4Xpresso ничего особенного нет:
Менеджер памяти
Пожалуй одна из самых сложных и запутанных частей любой L4-подобной системы - это менеджер памяти (слово виртуальной я исключаю, т.к. она не поддерживается в Cortex-M3). Дело в том, что L4 поддерживает большое количество адресных пространств, между которыми возможны многоуровневые отображения (т.е. любой регион памяти может отображаться сколь угодно много раз). При этом следует учитывать следующие особенности Cortex-M3
-
Отстутствует MMU, виртуальная память и страницы, однако есть MPU, позволяющий изолировать адресное пространство
-
Малое количество оперативной памяти, однако все адреса - 32-х битные, что требует экономить ее в структурах данных. В итоге удалось сжать структуру fpage_t до 4-х 32-х битных слов (16 байт).
-
В отличие от страничной адресации в x86 платформе, когда таблицы PDE и PTE хранятся в памяти, а TLB заполняется автоматически, в Cortex-M3 MPU надо самостоятельно программировать и он вмещает всего 8 регионов.
В L4 абстракцией представляющей сегмент памяти является т.н. гибкая страница (fpage, flexible page). Однако заметим, что в L4 все адреса и размеры fpage должны быть выровнены по 1024 байтам, что недопустимо в системах с столь малым количеством RAM, как L4Xpresso. Итак, при управлении памятью используются следующие структуры:
-
Гибкая страница fpage_t
-
Адресное пространство as_t
-
Пул памяти mempool_t
Карта памяти memmap создается при сборке ядра (см. kernel/src/memory.c) и представляет все пулы памяти, доступные ядру или пользователю. Частично она может быть известна и пользовательским процессам через служебную таблицу KIP.
В L4Xpresso в отличие от других L4 систем отстутствуют жесткие требования к базовым адресам и размерам регионам памяти, отображаемым через элемент межпроцессной коммуникации MapItem: они должны быть выровнены по минимальному размеру региона MPU. Это приводит к довольно сложным алгоритмам управления гибкими страницами. Предположим поток получает от корневого область памяти в 384 байта. Однако все регионы MPU могут быть только размером в степень двойки, таким образом надо создать цепочку из fpage (fpage chain): 256 и 128 байт. После этого поток отображает последние 256 байт в другой поток. В этом случае нам надо разрезать первую fpage на две, что и делает функция split_fpage. Все эти алгоритмы находятся в файле kernel/src/fpage.c , однако даже они не полностью реализуют необходимый функционал.
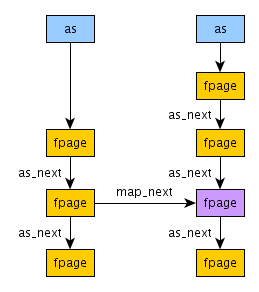
Адресное пространство представляет из себя односвязный список fpage, связанных указателями as_next, тогда как при отображении fpage создается ее копия в принимающем адресном пространстве (см. функцию map_fpage) и они связываются в циклический список:
Функция as_setup_mpu настраивает MPU при переключении контекста. При этом некоторые fpage отображаются в любом случае (они имеют флаг FPAGE_ALWAYS) - например это регионы программного кода, все остальные наполняются по остаточному принципу. Кроме того один слот всегда используется для страницы, в которой только что произошел сбой MemFault. Сам сбой MemFault обрабатывается в файле kernel/src/platform/mpu.c
Системные вызовы и IPC
До сих пор L4Xpresso была совершенно неюзабельной системой, т.к. пользовательские потоки не могут ничего делать без системных вызовов и межпотокового взаимодействия (по традиции оно называется в L4 межпроцессным, то есть IPC). В Cortex-M3 есть специальная ассемблерная инструкция для системного вызова - SVC #<номер системного вызова> (SVC - SuperVisor Call), однако параметры приходится размещать в регистрах или UTCB. Что интересно, Cortex-M3 никуда не копирует номер системного вызова, необходимо взять сохраненное значение PC и считать номер прямо из сегмента кода. При срабатывании обработчика прерывания SysCall, значения регистров сохраняются в контексте и их оттуда можно извлечь. Также при совершении IPC регистры используются для передачи данных (т.н. message-регистры). Еще одна особенность системных вызовов - это их малое количество, однако такие системные вызовы как ThreadControl или IPC имеют множественную семантику, что порождает лесеннку из if-else. Код этих подсистем расположен в файлах kernel/src/ipc.c и kernel/src/syscall.c
Ping-pong тест
Ну вот наш Proof-of-Concept готов, осталось только написать код корневого потока, от которого породить два: один постоянно передающий сообщения, а другой принимающий их (user/root_thread.c):
enum {PING_THREAD, PONG_THREAD};
static l4_thread_t threads[2] __USER_BSS;
void __USER_TEXT __ping_thread(void* kip_ptr, void* utcb_ptr) {
uint32_t msg[8] = {0};
while(1) {
L4_Ipc(threads[PONG_THREAD], L4_NILTHREAD, 0, msg);
}
}
void __USER_TEXT __pong_thread(void* kip_ptr, void* utcb_ptr) {
uint32_t msg[8] = {0};
while(1) {
L4_Ipc(L4_NILTHREAD, threads[PING_THREAD], 0, msg);
}
}
DECLARE_THREAD(ping_thread, __ping_thread);
DECLARE_THREAD(pong_thread, __pong_thread);
memptr_t __USER_TEXT get_free_base(kip_t* kip_ptr) {
kip_mem_desc_t* desc = ((void*) kip_ptr) + kip_ptr->memory_info.s.memory_desc_ptr;
int n = kip_ptr->memory_info.s.n;
int i = 0;
for(i = 0; i < n; ++i) {
if((desc[i].size & 0x3F) == 4)
return desc[i].base & 0xFFFFFFC0;
}
return 0;
}
#define STACK_SIZE 128
void __USER_TEXT __root_thread(kip_t* kip_ptr, utcb_t* utcb_ptr) {
l4_thread_t myself = utcb_ptr->t_globalid;
char* free_mem = get_free_base(kip_ptr);
uint32_t msg[8] = {0};
/*Allocate utcbs and stacks in Free memory region*/
char* utcbs[2] = {free_mem, free_mem + UTCB_SIZE};
char* stacks[2] = {free_mem + 2*UTCB_SIZE, free_mem + 2*UTCB_SIZE + STACK_SIZE};
threads[PING_THREAD] = L4_THREAD_NUM(PING_THREAD, kip_ptr->thread_info.s.user_base); /*Ping*/
threads[PONG_THREAD] = L4_THREAD_NUM(PONG_THREAD, kip_ptr->thread_info.s.user_base); /*Pong*/
L4_ThreadControl(threads[PING_THREAD], myself, 0, myself, utcbs[PING_THREAD]);
L4_ThreadControl(threads[PONG_THREAD], myself, 0, myself, utcbs[PONG_THREAD]);
L4_Map(myself, stacks[PING_THREAD], STACK_SIZE);
L4_Map(myself, stacks[PONG_THREAD], STACK_SIZE);
L4_Start(threads[PING_THREAD], ping_thread, stacks[PING_THREAD] + STACK_SIZE);
L4_Start(threads[PONG_THREAD], pong_thread, stacks[PONG_THREAD] + STACK_SIZE);
while(1) {
L4_Ipc(L4_NILTHREAD, L4_NILTHREAD, 0, msg);
}
}
DECLARE_THREAD(root_thread, __root_thread);
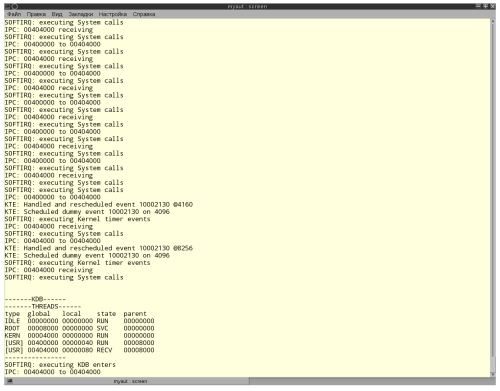
Как видно из скриншота, они действительно делают это :)
Исходники проекта располагаются на github: https://github.com/myaut/l4xpresso


