Недавно занимался проблемой производительности в следующей конфигурации:
- Два хоста в HA-кластере Veritas Cluster Server
- Два хранилища IBM V3700, зеркалируемые средствами Veritas Volume Manager
- Хранилища подключены к хостам по FC
- На хостах крутится Windows 2012 R2 и на одном из них средствами VCS поднимается MS SQL Server 2008 SP4.
Всё это жило и работало, пока MS SQL Server не начал рапортовать в логи о событии 833 (время выполнения операции ввода/вывода превысило 15 секунд), а рабочие в цеху не стали жаловаться, что роботы тупят (роботы ходят в базу). На самом деле, подобная проблема проявлялась уже не в первый раз, но причина каждый раз оказывалась новой.
Проверив уже известные проблемные места и не обнаружив там ничего, мы стали смотреть на производительность хранилищ и заметили довольно интересную особенность.
Напоминаю, у нас имеется два одинаковых хранилища, операции записи на которые производятся синхронно. Когда мы дали на хранилища нагрузку случайной записью блоками от 64К (64K - рекомендованный размер блока для файловой системы, на которой лежат файлы базы MS SQL Server), то получили следующие графики:
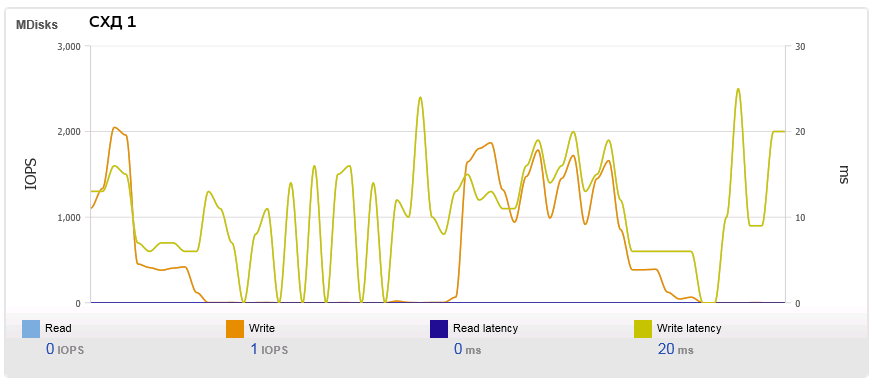
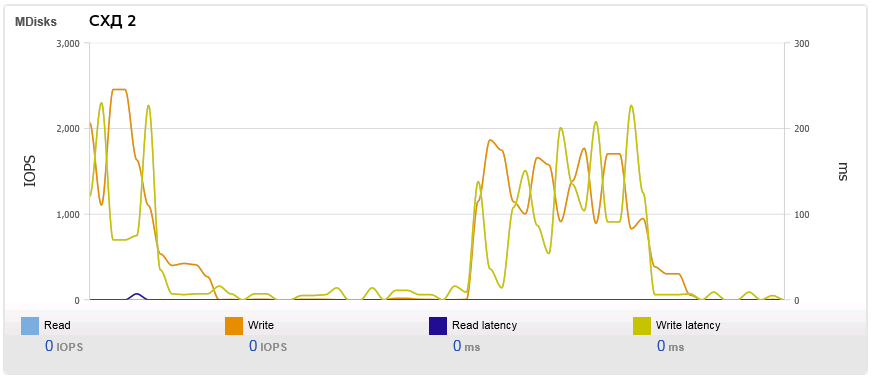 Первое что бросается в галаза - это кривая IOPS забором. Вместо того, чтобы упереться в максимум, количество IOPS периодически проседает и затем снова подлетает. Второе - это разница в задержке (Latency) на порядок - Вау! одинаковые СХД и такая разница в задержке. Третье - это характер кривой Latency. На первой СХД задержка снижается вместе с IOPS - система как будто расслабляется в эти моменты. На второй СХД наоборот, проседание IOPS приходится аккурат на пик Latency - система как будто захлёбывается.
Первое что бросается в галаза - это кривая IOPS забором. Вместо того, чтобы упереться в максимум, количество IOPS периодически проседает и затем снова подлетает. Второе - это разница в задержке (Latency) на порядок - Вау! одинаковые СХД и такая разница в задержке. Третье - это характер кривой Latency. На первой СХД задержка снижается вместе с IOPS - система как будто расслабляется в эти моменты. На второй СХД наоборот, проседание IOPS приходится аккурат на пик Latency - система как будто захлёбывается.
Эти две картинки дали нам основание для дальнейшего тестирования и эскалации в IBM. Фактически, мы повторили нагрузочные тесты несколько раз, чтобы убедится в их повторяемости, отключили зеркалирование и прогнали те же тесты на каждой СХД отдельно. На нашем наборе данных, мы получили следующие результаты:
| |
IOPS, writes/s |
Throughput, MB/s |
Latency, ms |
| СХД 1 |
~2500 |
~150 |
<25 |
| СХД 2 |
~1600 |
~100 |
100-200 |
Причём графики IOPS и Latency на первой СХД колеблются адекватно, на второй же снова "забор":
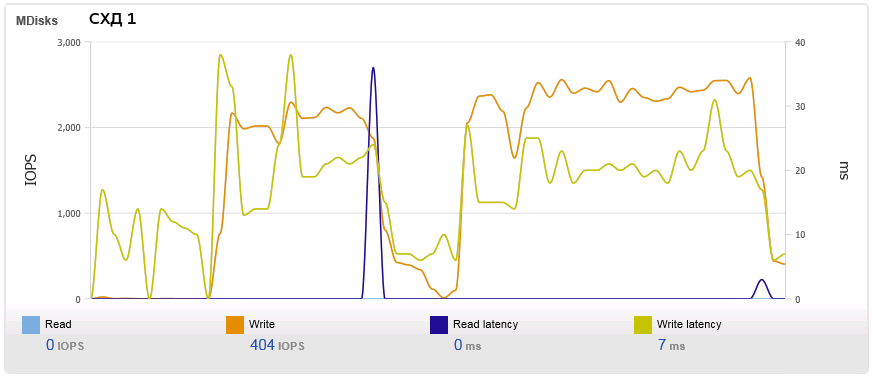
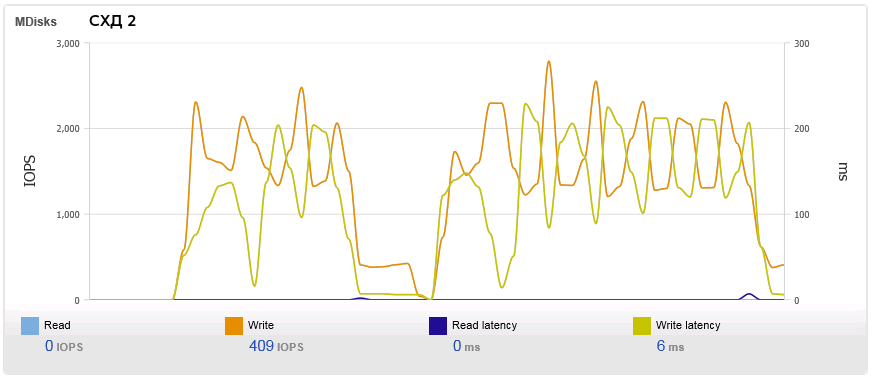 Также мы собрали SNAPы с хранилищ во время одного из тестовых прогонов и снабдили всей этой информацией техподдержку IBM.
Также мы собрали SNAPы с хранилищ во время одного из тестовых прогонов и снабдили всей этой информацией техподдержку IBM.
Результат не заставил себя долго ждать - по собранной статистике инженеры IBM заметили, что один из дисков второй СХД - "медленный", то есть обрабатывает операции заметно дольше остальных.
Диск был оперативно заменён и вуаля! Забор с графиков пропал, производительность хранилищ выровнялась, исходная проблема с базой ушла.
Также, как нам сообщили в IBM, если бы рабочая нагрузка на СХД была ещё чуть-чуть выше, система сама бы зафейлила "медленный" диск. Но так как чуда не случилось, мы провели много прелестных мгновений, выискивая в этой конфигурации проблему.

