Конфигурация СХД
- Huawei Oceanstor 2600 версии V300R006C20 Enhanced.
- Контроллерное шасси на 12 слотов 3.5", без полок.
- High Performance Tier: SAS SSD 600GB, 4шт.
- Capacity Tier: NL-SAS 2TB, 8шт, RAID 5, hot spare policy low (соответствует ёмкости одного накопителя).
Что произошло
В отличие от незапамятного Storwize V3700 (про который у меня есть
заметка с аналогичной проблемой), Oceanstor сам показал алармы, следующего содержания:
На указанном диске CTE0.1 уже горит красный индикатор и это даже видно в DM, хотя статусы диска всё ещё Normal и Online. То есть он продолжает использоваться системой. Первый аларм сообщает о том, что всё зарезервированное пространство было выделено под данные с проблемного диска и оно резко закончилось:
Также, если обращать внимание на статус дискового домена или пула хранения, можно заметить, что массив периодически выполняет Pre-copy, то есть копирует очередную порцию данных в зарезервированную область.
Вот, что было на графиках в реальном времени:
На нижнем графике видим как "пляшет" задержка чтения. На верхнем отображена утилизация накопителей, СХД уже активно разгружает медленный диск. Это также заметно по распределению данных дискового домена:
Если посмотреть исторический график за прошедший месяц, на нём становится отчётливо видно как именно СХД работает с диском после произошедшего (CTE0.1 красного цвета).
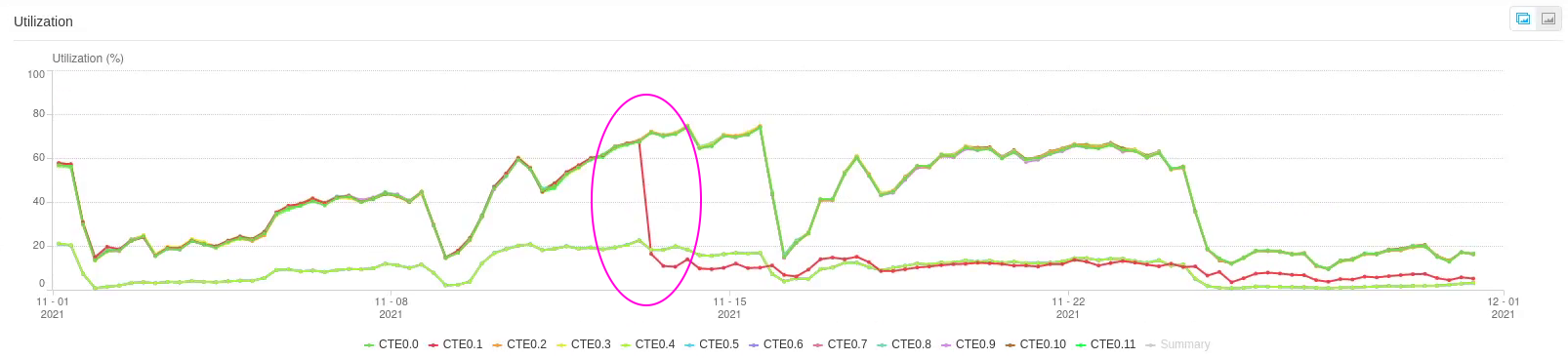
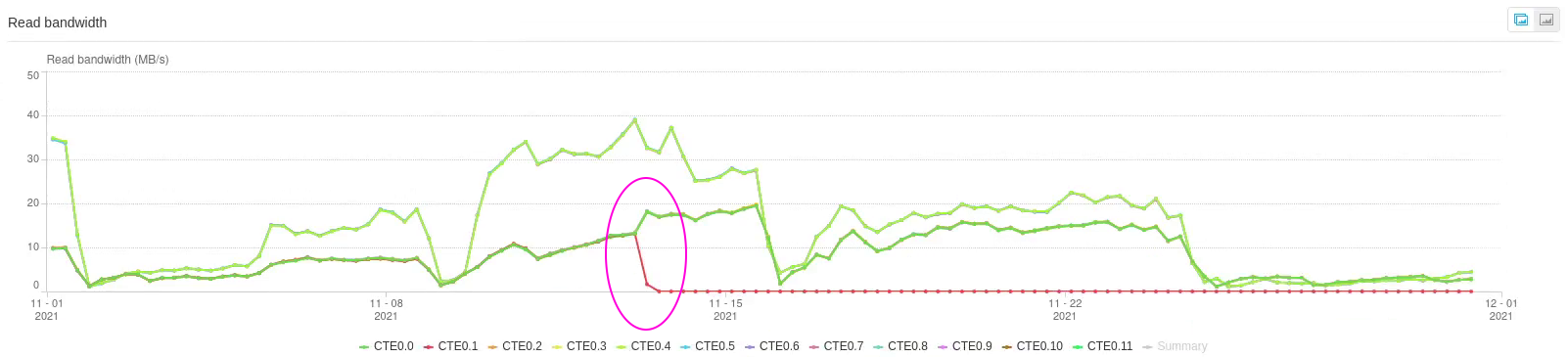
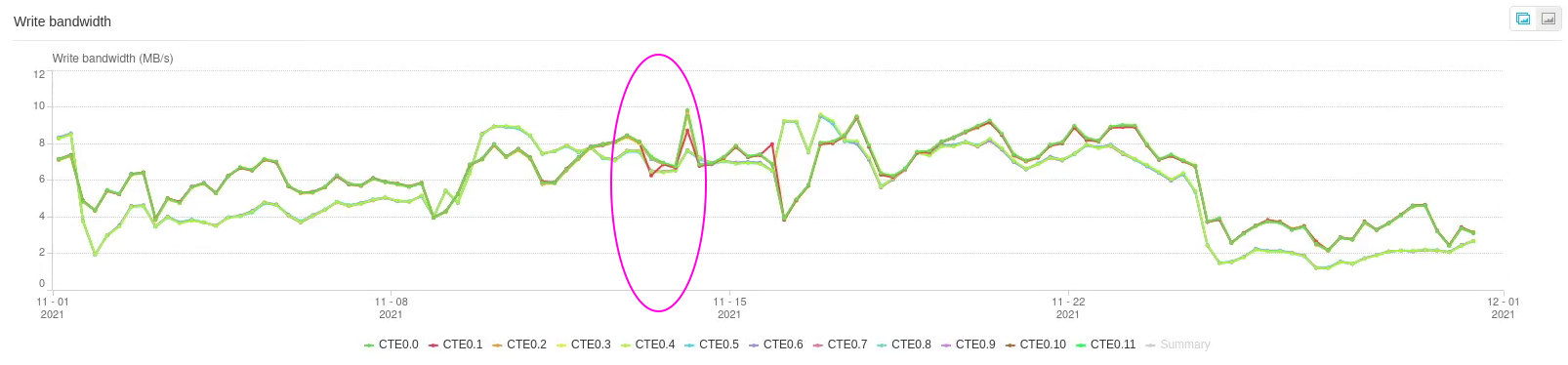
Эллипсами обозначено примерное время возникновения аларма на СХД. Из-за усреднения значений на графике за такой срок уже не видно самой проблемы, но зато видно реакцию массива.
Как видим, чтобы снизить влияние медленного диска, СХД перестаёт читать с него данные (из-за того, что операции чтения синхронные, как сразу же подметил мой коллега,
Дмитрий), но продолжает записывать в режиме Write Back.
Обращение в тех. поддержку Huawei
Логинимся в
https://support.huawei.com/enterprise. Жмём кнопки Service Request -> Create SR, указываем серийный номер СХД. Серийный номер можно увидеть на домашней странице в DeviceManager или сразу после логина в CLI. Далее описываем проблему.
В ответ на наше обращение поддержка запросила логи, которые можно собрать в меню Settings -> Export Data -> System Log. Скриншот из оригинальной инструкции:
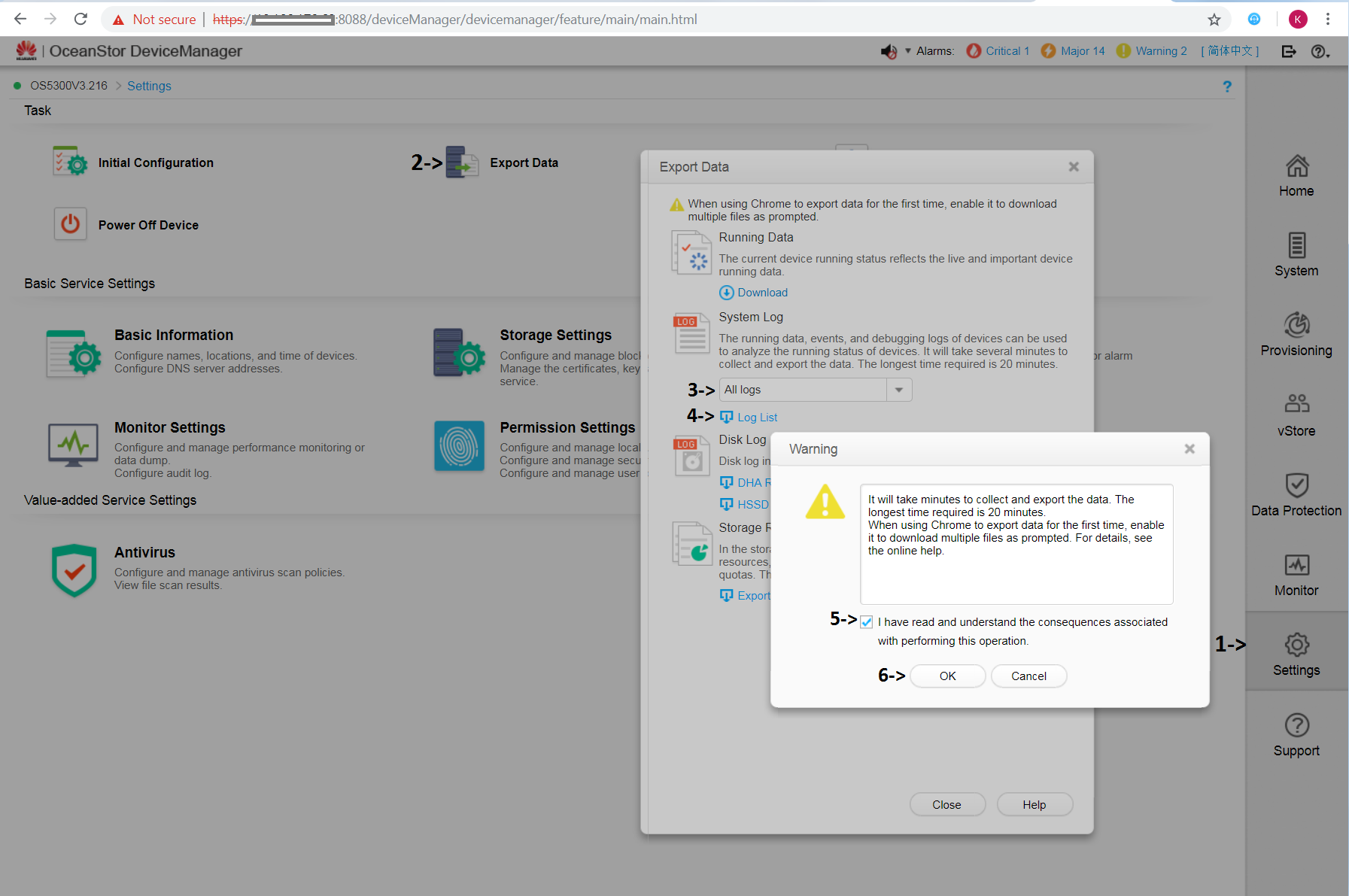
В принципе, логи можно приложить сразу же, при регистрации обращения.
После анализа логов инженер поддержки сразу принял решение о необходимости замены. Диск был доставлен на следующий рабочий день.
SmartKit
Диск является CRU, а значит замену можно производить самостоятельно с использованием SmartKit CRU Replacement Tool.
В нашем случае диск является коффером (Coffer disk), однако процедура его замены не отличается от замены обычного диска.
Логинимся в
https://support.huawei.com/enterprise. Идём в раздел Centralized Storage -> Data Management and Operation -> SmartKit -> Software Download. Выбираем последнюю версию, на новой странице скачиваем архивы SmartKit_VERSION.zip и SmartKit_VERSION_Tool_cru.zip.
Первый архив рапаковываем, устанавливаем, запускаем SmartKit. Скармливаем ему второй архив в меню Function Management -> Import. Теперь в разделе Parts Replacement доступна соответствующая кнопка:
Замена
Процедура замены хорошо описана в
документации, есть даже
видео, но тут возникла пара моментов...
В нашем случае диск всё ещё Online, поэтому SmartKit говорит "the system does not have this type of faulty components":
Очевидно, нужно ещё раз убедиться, что подключились к нужному массиву, убрать галочку вверху и не ошибиться при выборе диска. Здесь идентифицировать диск поможет Location. CTE0.1 означает Controller Enclosure 0, slot 1. Именно это расположение было указано в аларме. (А вот пример для диска в дисковой полке: DAE2.11 - Disk Array Enclosure 2, slot 11.)
SmartKit начал выполнять проверку перед заменой:
В процессе диск перешёл в состояние About to fail:
Спустя час SmartKit вывалил ошибку с тайм-аутом, но повторная проверка прошла успешно.
Диск был заменён и начался ребилд:
После завершения процесса восстановления, загрузка и заполнение дисков выравнялись. Алармы были автоматически очищены. Система вернулась к нормальной работе без каких-либо плясок с бубном и долгих переписок с поддержкой, в отличие от некоторых...

