Синопсис
С активным развитием и повсеместным распространением различного рода информационных систем все чаще появляется необходимость обеспечить возможность передачи данных между системами. При этом форматы представления данных в разных системах могут отличаться друг от друга, поэтому необходима возможность трансформации передаваемых данных и их преобразования к необходимому виду.
В качестве инструмента для обеспечения интерфейса обмена данными между информационными системами может использоваться программное обеспечение Apache NiFi. Данный продукт представляет собой open source ETL/ELT-инструмент для работы с данными, он предоставляет возможности как для извлечения данных из различных источников (extraction), так и для трансформации (transformation), и для загрузки данных (loading).
Компания Tune-It уже несколько лет успешно занимается разработкой решений по управлению потоками данных на базе платформы Apache NiFi, включающих в себя:
- возможность инициации процесса передачи данных посредством HTTP-запросов;
- получение данных из одной информационной системы и отправки данных в другую;
- логирование данных, проходящих через систему, на каждой стадии потока обработки;
- конвертацию получаемых данных между форматами CSV, JSON, XML;
- обработку ошибок, возникающих при передаче данных, с возможностью повторной обработки объектов и отправки отчетов об ошибках на почту.
Не стремясь полностью покрыть все многочисленные возможности Apache NiFi (а их действительно много, NiFi поддерживает работу с HDFS, Hive, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ и многими другими системами), в небольшом цикле статей на примере типового потока обработки данных мы постараемся разобрать основные принципы разработки, которыми мы руководствуемся при построении систем на основе Apache NiFi. Кроме того, разберем некоторые “best practices”, которые позволят упростить процесс разработки, порассуждаем о том, когда стоит прибегнуть к написанию кода, а когда можно ограничиться средствами платформы и процессорами “из коробки”, и многое другое. Ключевые концепции подхода к разработке интерфейса обмена данными, которые будут описаны, могут быть применены ко многим типовым случаям взаимодействия двух систем с различием в способах обработки передаваемых данных.
Перед тем, как приступить к созданию нашего потока обработки, скажем еще пару общих слов о NiFi как таковом и опишем наши гипотетические информационные системы, между которыми и будет происходить обмен данными.
Основы Apache NiFi
Apache NiFi может быть скачан отсюда: https://nifi.apache.org/download.html. После установки NiFi для запуска необходимо в его директории запустить
./bin/nifi.sh start
Для остановки вместо start используется stop. Также полезны команды restart и status. После запуска будет доступен веб-интерфейс. Порт по умолчанию 8443. Для замены надо найти в ./conf/nifi.properties похожие строчки:
nifi.web.https.host=127.0.0.1
nifi.web.https.port=8443
и поменять хост и порт в случае необходимости.
При запуске NiFi вас перенаправит на окно логина:
Чтобы узнать данные для входа необходимо перейти в домашнюю директорию NiFi, оттуда в /logs/nifi-app.log и найти там подобные строчки для входа:
Generated Username [<username>]
Generated Password [<password>]
Теперь мы готовы к работе. Основная работа по организации потока обработки данных осуществляется посредством процессоров (Flow File Processor), представляющих собой блоки в веб-интерфейсе и выполняющих определенные функции. Среди них, например, процессоры для обеспечения возможности обращаться к NiFi через HTTP запросы, а также посылать ответы на них; для замены текста; для навигации данных потока в зависимости от условия; и многие другие. Добавляются они следующим образом:

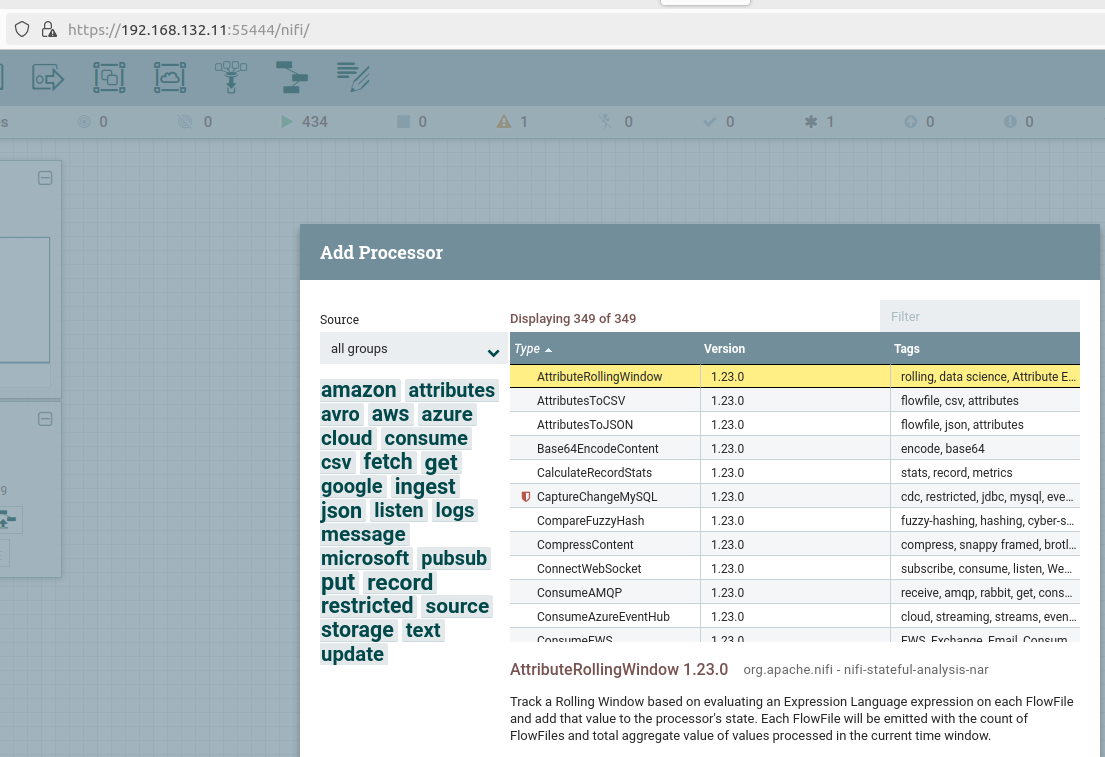
Сами передаваемые данные представляют собой файл потока (Flow file), состоящий из различных атрибутов (метаинформации о данных) и непосредственно самих данных (payload). Передача этих данных между блоками осуществляется по стрелкам (Connections), при этом предусмотрена возможность навигации в зависимости от результата выполнения предыдущего блока. В общем случае потоки файлов, обработанные без ошибок, формируют выполненную очередь (success queue), а сообщения с ошибками передаются в failure queue. Существуют и другие типы соединений в зависимости от конкретного процессора. Например, такие соединения можно задавать самостоятельно в процессорах RouteOnAttribute, позволяющих регулировать поток обработки в зависимости от условия. Простейший поток обработки данных выглядит примерно так, как нарисовано ниже (все процессоры (пока что) случайны). В данном примере процессорами являются прямоугольные блоки со своими функциями. Между ними есть соединения со стрелками, показывающими направление передачи данных, и очередями, в которых скапливаются данные до тех пор, пока следующий процессор не сможет их обработать.

Процессоры также можно организовывать в группы для логической организации потока. Например, группа для валидации поступившего запроса:
Внутри групп процессоров есть входные и выходные порты для обозначения начала обработки данных в группе и ее окончания (ниже это request и checked request):
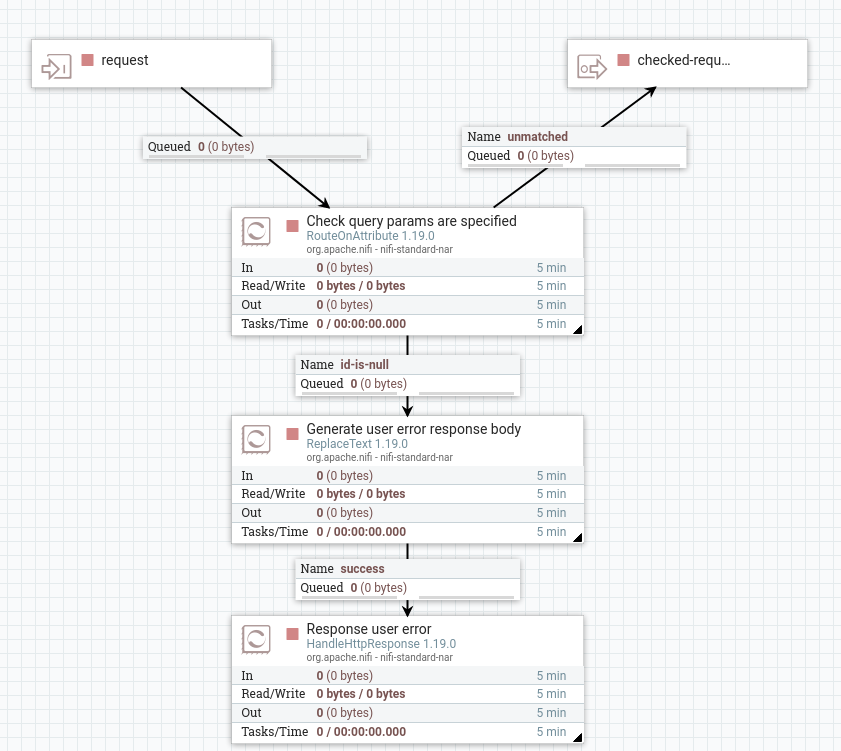
Этих базовых знаний достаточно для общего понимания и запуска NiFi. По надобности будем вводить новое, а для более полного погружения и понимания рекомендуем также прочитать документацию (https://nifi.apache.org/documentation/v1/).
Как будет выглядеть поток обработки
Кратко опишем, что вообще будет представлять наш тестовый проект. Предположим, что есть две информационные системы, которые мы красноречиво назовем SYS1 и SYS2. Трансфер будет организован следующим образом:
- NiFi получает запрос на передачу данных, который содержит сведения о необходимом типе трансфера данных (что конкретно передавать из SYS1 в SYS2), а также идентификатор объекта, который необходимо передавать, и формирует на его основе FlowFile
- В этот FlowFile записываются атрибуты - разного рода метаинформация, полезная для дальнейшей обработки
- Происходит валидация запроса - проверка на наличие всех необходимых параметров для данного типа трансфера
- В соответствии с указанным идентификатором объекта NiFi достает данные из SYS1, которые преобразовывает к виду, в котором данные смогут быть обработаны SYS2
- Происходит отправка обработанных данных в SYS2 с получением ответа от нее
- NiFi формирует ответ на HTTP-запрос, отправленный ему изначально
- В случае возникновения проблем данные отправляются в обработчик ошибок, где весь процесс повторяется заданное число раз
- В случае, если повторная отправка данных не привела к положительному результату после определенного времени, на почту отправляется письмо с информацией по ошибкам
Совсем скоро все это станет нагляднее и понятнее по мере продвижения по проекту.
Что будем делать дальше
В следующей части мы будем разбирать то, как стоит начинать трансфер, как принимать HTTP-запросы, как организовать заполнение атрибутов FlowFile’ов в зависимости от типа передаваемой информации, и какую метаинформацию будет полезно добавить вне зависимости от особенностей конкретного трансфера.

