В канун нового года хочется чтобы все плохое осталось в старом году, а хорошее - перешло новый. У меня плохое в уходящем году ассоциируется с некоторыми необычными (и неприятными) багами Solaris Cluster, некоторые из которые уже удалось починить, а некоторые еще в процессе. Они довольно специфичны, но поэтому плохо документированы.
Взаимоблокировка между prctl и clrs в зоне
Данная проблема проявлялась, если для ресурсной группы, запускаемой в зоне, настроен CPU control usage (он описан здесь: http://docs.oracle.com/cd/E19575-01/820-7358/gbylg/index.html), и в ресурсной группе вызывается команда clrs, гасящая ресурс (в моем случае это был скрипт бекапа). В этом случае она должна сходить на RGM на глобальной зоне, и там вызвать prctl, чтобы переконфигурировать процессорные ресурсы, выделенные зоне. И к сожалению, между этими двумя процессами происходит взаимоблокировка:
1725 /usr/cluster/lib/sc/rpc.fed
6223 sh -c /usr/bin/prctl -n zone.cpu-shares -v 1 -r -i zone myzone 2>&
6224 /usr/bin/prctl -n zone.cpu-shares -v 1 -r -i zone myzone
В threadlist видно, что она ожидает процесса (хотя это явно не видно, это процесс clrs):
PC: cv_wait_sig_swap_core+0x130 CMD:
/usr/bin/prctl -n zone.cpu-shares -v 1 -r -i zone myzone
stack pointer for thread 300889b2200: 2a107b669c1
[ 000002a107b669c1 cv_wait_sig_swap_core+0x130() ]
pr_wait+0x10()
pr_wait_stop+0x1bc()
pr_control+0x350()
prwritectl+0xf4()
prwrite+0x17c()
fop_write+0x20()
write+0x268()
В итоге заказчик полностью перезагрузил кластер.
На эту тему у Oracle есть баг: 15863300 clrs command hangs - deadlock between remote invocation code and prctl command, который закрывается патчем 145333-21. Однако установка патчей приводит к куда более интересным последствиям.
Ломаем телеметрию патчами на Solaris Cluster
Чтобы починить эту проблему, было принято решение поставить патчи - причем сразу большущими бандлами патчей на Solaris и Cluster с EIS-DVD. К сожалению, после этого ломается кластерная телеметрия. Телеметрия позволяет осуществлять мониторинг потребления ресурсов (пара слов о ней есть здесь: http://docs.oracle.com/cd/E18728_01/html/821-2682/gctmw.html ). И, к сожалению после установки свежих патчей, ее ресурсная группа падает в Online_faulted.
В логах CACAO видно исключение Java:
Nov 7, 2013 5:59:17 PM com.sun.cacao.commandstream.impl.shell.Shell run
FINE: thr#13 Exception thrown while executing [com.sun.cluster.agent.ganymede:scslmthreshCmdStream -motype mot.sunw.disk
-motype mot.sunw.cluster.resourcegroup -motype mot.sunw.node
-motype mot.sunw.netif -motype mot.sunw.solaris.zone -kiname ki.sunw.rbyte.rate -kiname ki.sunw.wbyte.rate -kiname ki.sunw.write.rate
-kiname ki.sunw.read.rate -kiname ki.sunw.mem.used -kiname ki.sunw.swap.used -kiname ki.sunw.cpu.used -kiname ki.sunw.cpu.idle
-kiname ki.sunw.cpu.iowait -kiname ki.sunw.cpu.loadavg.1mn
-kiname ki.sunw.cpu.loadavg.5mn -kiname ki.sunw.cpu.loadavg.15mn
-kiname ki.sunw.mem.free -kiname ki.sunw.swap.free -kiname ki.sunw.ipacket.rate
-kiname ki.sunw.opacket.rate -all]
java.lang.Exception: command not found [com.sun.cluster.agent.ganymede:scslmthreshCmdStream]
at com.sun.cacao.commandstream.impl.Registry.findCommand(Registry.java:115)
at com.sun.cacao.commandstream.impl.shell.Shell.run(Shell.java:296)
at com.sun.cacao.commandstream.impl.CommandStreamAdaptor$ClientRun$1.run(CommandStreamAdaptor.java:691)
at java.security.AccessController.doPrivileged(Native Method)
...
В messages есть более интересные ошибки:
Nov 6 05:22:18 m4000-1 cacao:default[2794]: [ID 702911 daemon.warning] com.sun.cluster.agent.ganymede.PermanentStorage.permanentlySave : java.io.NotSerializableException: com.sun.cluster.agent.ganymede.AggregateResult
Nov 6 05:23:16 m4000-1 cacao:default[2794]: [ID 702911 daemon.warning] com.sun.cluster.agent.ganymede.PermanentStorage.permanentlyRestore : java.io.WriteAbortedException: writing aborted; java.io.NotSerializableException: com.sun.cluster.agent.ganymede.AggregateResult
Nov 6 05:23:19 m4000-1 java[2794]: [ID 513556 daemon.warning] Failed to read the table scslmthresh: error = 113
К сожалению, эти сообщения совершенно не указывает на причину ошибки. А вот, если включить расширенные логи, то все встает на свои места. Задерем у классов из пакета ganymede уровень логов до максимального (FINEST):
cacaoadm list-filters |
awk -F= '/ganymede/ { print $1; }' |
( while read DOMAIN
do cacaoadm set-filter -p $DOMAIN=FINEST
done )
И в логах cacao появятся куда более информативные сообщения:
FINER: thr#37 THROW
java.sql.SQLSyntaxErrorException: 'MINIVALUE' is not a column in table or VTI 'APP.WEEKLYMEASURES'.
Структура базы данных телеметрии поменялась после установки патчей (!). Это связано с тем, что в новых версиях JavaDB (Derby) названия MINVALUE и MAXVALUE стали зарезервированными. Лечится переименованием колонок. Для этого запустим netstat, и узнаем IP, на котором слушает Derby:
bash-3.2# netstat -an | grep 1527 | grep LISTEN
172.16.4.1.1527 *.* 0 0 49152 0 LISTEN
Подключимся к Derby:
# export DERBY_HOME=/opt/SUNWjavadb
# sh /opt/SUNWjavadb/bin/ij
ij> connect 'jdbc:derby://172.16.4.1:1527/APP';
ij> describe WEEKLYMEASURES;
Для ij >= 10.3 можно использовать RENAME COLUMN.
ij> RENAME COLUMN WEEKLYMEASURES.MINVALUE TO MINIVALUE;
ij> RENAME COLUMN WEEKLYMEASURES.MAXVALUE TO MAXIVALUE;
В старых Derby этого выражения нет, поэтому придется сделать переименование грязнее.
ij> ALTER TABLE WEEKLYMEASURES ADD MINIVALUE BIGINT;
ij> UPDATE WEEKLYMEASURES SET MINIVALUE = MINVALUE;
ij> ALTER TABLE WEEKLYMEASURES DROP COLUMN MINVALUE;
ij> ALTER TABLE WEEKLYMEASURES ADD MAXIVALUE BIGINT;
ij> UPDATE WEEKLYMEASURES SET MAXIVALUE = MAXVALUE;
ij> ALTER TABLE WEEKLYMEASURES DROP COLUMN MAXVALUE;
После этих действий телеметрия поднимается, но графики, увы не рисуются. Это связано с тем, что в SunClusterManager - управлялкой, интегрированной в WebConsole используется библиотека JFree, и файлы этой библиотеки тупо копируются, что видно в postinstall-скрипте:
# use only jfreechart and jcommon
JFREECHART_JAR_LIBS="${JFREECHART_DIR}/share/lib/SUNWjfreechart/jfreechart.jar \
${JFREECHART_DIR}/share/lib/SUNWjfreechart/lib/jcommon.jar"
...
for i in ${JFREECHART_JAR_LIBS}; do
/usr/bin/cp $i ${CONSOLE_DIR}/SunClusterManager/WEB-INF/lib
done
Если поднять уровень логирования веб-консоли, то можно видеть ругань, на отсутствующий Java-метод:
Exception java.lang.NoSuchMethodError: org.jfree.data.time.TimeSeries.<init>(Ljava/lang/Comparable;Ljava/lang/Class;)V
Дело в том, что изначально с SunClusterManager поставляется JFree 1.0.8, затем устанавливается патч на кластер, требующий новой версии JFree. Но даже, если поставить патч c JFree 1.0.13, управлялка просто не знает о ее существование. Решение - просто заново скопировать библиотеки.
Непростая сеть и недоступный кластер
В данном случае инфраструктура кластера чуть сложнее чем СХД + Сервер + Сервер. Я ее показал на картинке:
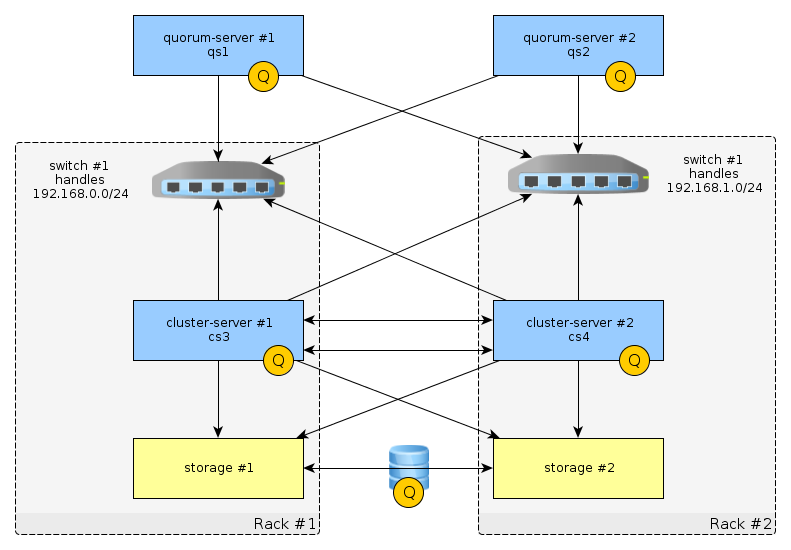
И при выключении одной из стоек, узел во второй падает в панику - такая вот высокая доступность. Слушатели наших курсов D74942GC10 и D68179GC30 заметят, что свитчи не задублированы, и конфигурация некорректна. Но это должно приводить к сбою ресурсной группы, а не панике узла. Разберемся с этой ситуацией подробнее. Замечены были паники двух типов.
В первом случае, кластер не успевал достучаться вовремя до кворум-сервера, и сообщение о панике выглядело так:
Unable to acquire the quorum device.
Можно увеличить время таймаута доступа к серверу (ну и неплохо бы, переконфигурировать коммутаторы, поотключав всякие медленные STP):
phys-schost# vi /etc/system
...
set cl_haci:qd_acquisition_timer=700
Вторая паника несколько сложнее, ее сообщение выглядит так:
Failfast: timeout - unit "failfast_now"
Проанализировав crashdump, выяснилось следующее:
1. Вместе cо второй стойкой падает коммутатор 2, обеспечивающий подсеть 192.168.1.0/24
2. Это приводит к невозможности запустить ресурс res1-lh2, что видно в логах:
Jul 9 07:56:47 cs3 Cluster.RGM.global.rgmd: [ID 494478 daemon.notice] resource res1-lh2 in resource group res-rg has requested failover of the resource group on uvd3.
3. Чтобы перезапустить ресурсную группу res1-lh2, кластер запускает процесс hafoip_retry, что видно в крешдампе ядра:
CAT(vmcore.13/10X)> proc | grep hafoip
0xfffffe98c2668750 26446 2381 0 7213056 3727360 1011712 0 /usr/cluster/lib/rgm/rt/hafoip/hafoip_retry res1-rg res1-lh2 sc_ipmp1
0xfffffe98c1e0a058 26441 2381 0 7221248 3735552 1019904 0 /usr/cluster/lib/rgm/rt/hafoip/hafoip_retry res2-rg res2-lh2 sc_ipmp1
0xfffffe98cdf62ac0 26436 2381 0 7221248 3735552 1019904 0 /usr/cluster/lib/rgm/rt/hafoip/hafoip_retry res3-rg res3-lh2 sc_ipmp1
4. Те в свою очередь дергают демона rgmd, который падает и это приводит к панике системы.
Это связано с багом в демоне rgmd. У Oracle зарегистрирован баг и есть IDR PATH, который решает эту проблему, но я пока его не тестировал.
Все названия ресурсов, ресурных групп и хостов изменены, а совпадения считаются случайными.


