Сегодня поговорим о такой малоизвестной мере оценки деятельности ученого как семантометрия. Семантометрия – это метод оценки научного исследования, построенный на предположении, что для оценки значимости публикации нужен полный текст. Предпосылкой к появлению подобного класса методов являются недостатки методов научной оценки, основанных на цитируемости статьи и количестве полученных ссылок. Основная причина возникновения семантометрии состоит в том, что несмотря на преимущество методов оценки на основе ссылок, среди которых простота и хорошая доступность данных цитирования, они не всегда обеспечивают достаточное свидетельство влияния, качества и научного вклада. Это происходит из-за того, что при анализе цитирования не учитываются многие факторы - изменение отношения (позититвное, негативное), семантику ссылки (сравнение, фактическая информация, определение и т.д.), контекст ссылки (гипотеза, анализ, результат и т.д.), мотивы цитирования, популярность тем, величину научных сообществ, временную задержку появления ссылок и другие.
Семантометрия же является автоматизированный метрикой, использующей полный текст. Полагается, что статья вносит вклад в науку, если она создает связь между тем, что уже известно, и чем-то новым. При этом наибольший вклад вносит статья, объединяющая наиболее отдаленные друг от друга области научного знания.
Сама идея семантометрии предложена в 2014 году Петром Кнотом и Драгомирой Германовой из Открытого университета Великобритании и изложена в их статье «Towards Semantometrics: A New Semantic Similarity Based Measure for Assessing a Research Publication's Contribution». Дальнейшие исследования в этой области так или иначе ссылаются на эту статью. Согласно гипотезе авторов статьи, влияние публикации р может оцениваться на основе семантического расстояния между публикациями, цитируемыми р (множество А), и публикациями, цитирующими р (множество В). То есть на основе того, насколько далеки друг от друга по смыслу статьи, которые ссылаются на публикацию и статьи, на которые ссылается публикация. Как уже говорилось, наибольший вклад вносит статья, образующая самый длинный «мост» между разными областями науки, поскольку считается что, соединяя существующие знания, такая междисциплинарная статья послужит обширным фундаментом для построения новых знаний:
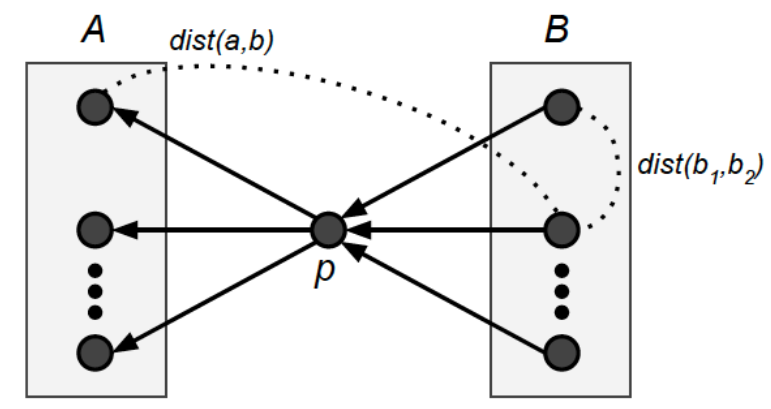
где
- p – вклад публикации;
- А – множество публикаций, цитируемых статьей;
- B - множество публикаций, цитирующих статью;
- dist – семантическая дистанция между статьями.
С учетом ранее сказанного была разработана формула, оценивающая вклад публикации, основывающаяся на измерении семантического расстояния между публикациями, цитируемыми р, и публикациями, цитирующими р. Сумма в уравнении используется для подсчета общего расстояния между всеми сочетаниями публикаций в множествах А и В. Это расстояние оценивается с помощью использования измерений семантического сходства на полных текстах публикаций, такое как косинусное сходство векторов документов tf-idf. Вторая дробь в уравнении является фактором нормализации, приспособленным ко всем комбинациям между членами множеств А и В, что приводит к среднему расстоянию между членами этих двух множеств. Первая дробь в выше приведенном уравнении является еще одним фактором нормализации, отвечающим за приспособление значения вклада к отдельной области и типу публикации. Он основан на измерении среднего внутреннего расстояния публикаций в рамках множеств А и В:
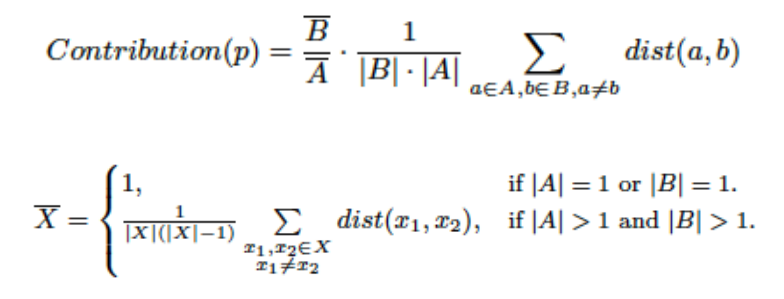
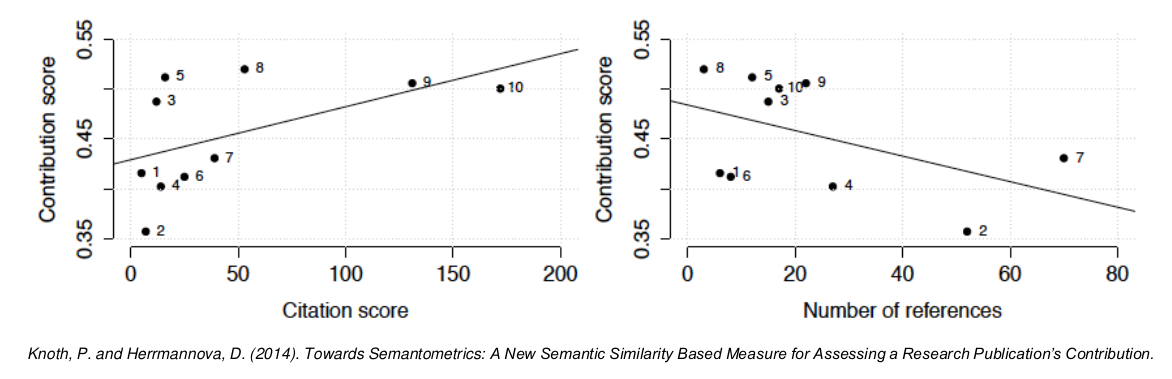
Для проверки своей гипотезы Кнот и Германова составили небольшой массив данных из 10 статей. На графиках они показаны нумерованными точками. На левом графике мы видим, как соотносятся рассчитанный вклад публикации и citescore - это численный показатель, отражающий среднее количество цитируемости статьи. На правом – зависимость от количества ссылок на другие статьи в рассматриваемой публикации. Линия на каждом из рисунков показывает линейную модель соответствия. Было установлено, что оценка вклада медленно растет с увеличением числа ссылок на публикацию. Это обусловлено тем, что вероятность того, что публикация обеспечивает высокий вклад усиливается с подсчетом ссылок, однако они не прямо пропорциональны. Например, в массиве данных можно найти публикации с оценкой ссылок ниже и относительно высокой оценкой вклада. Также можно сделать вывод, что с увеличением числа ссылок на другие статьи оценка вклада медленно снижается. Это отражает, что рост числа цитируемых документов не может непосредственно воздействовать на оценку вклада.
Теперь поговорим о том, где еще и для каких целей применяются идеи семантометрии. Одним из примеров является работа все тех же авторов, в которой предлагается подход к классификации научной коллаборации. Здесь применяется идея семантической дистанции между работами ученых, и так называемая research endogamy (термин введенный другим автором – Серджо Монтолио), характеризующая тенденцию авторов работать совместно с одними и теми же авторами или в пределах одной группы авторов. Для оценки семантической дистанции также используется полный текст - берется среднее значение семантических дистанций всех пар соавторов. На основе данных методов получилось разделить типы коллабораций на четыре группы:

Кроме того подход, основанный на анализе полного текста статьи, применяется для определения типа публикации. Например, в работе известных нам Кнота и Германовой «Analyzing Citation-Distance Networks for Evaluating Publication Impact» где сравниваются основополагающие статьи, дающие начало новому знанию и обзорные статьи. Было установлено, что семантическая дистанция между публикациями, которые ссылаются на статью, и публикациями, на которые ссылается статья, больше для основополагающей статьи, чем для обзорной, поскольку такие статьи оказывают большее влияние непосредственно на развитие науки. Обзорные статьи же носят преимущественно образовательный характер и как следствие содержат большое количество ссылок на другие статьи.
Теперь рассмотрим основные проблемы семантометрии. Главная проблема состоит в том, что семантометрия для наивысшей эффективности нуждается в неограниченном доступе к данным. Есть некоторые проблемы с открытым доступом к научным публикациям и в частности с автоматической обработкой таких публикаций. Даже для проведения эксперимента, описанного в публикации Кнота и Германовой, собрать тестовый массив данных было проблематично, не говоря уже о по-настоящему больших объёмах данных. Кроме того, цитируемые документы могут быть не только статьями, но и в перспективе веб-страницами, постами в блогах, отчеты и т.п. данных может быть достаточно много и получить ко всему доступ будет проблематично. Также возникают проблемы с дублированием и разрозненностью данных. Как следствие всего этого – достаточно тяжело доказать, что данная метрика может широко использоваться. Таким образом, существует потребность в провайдерах открытого доступа создающих один массив данных, распространяющийся на все научные дисциплины.
В заключение скажем, что благодаря семантометрии появляется возможность оценивать вклад статьи принимая во внимание сам ее текст, а не определенные атрибуты и число цитирований. Появляется возможность оценить вклад, как и недавно выпущенных статей, у которых еще нет большого числа ссылок, так и по тем или иным причинам редко цитируемых статей. Несмотря на определенные проблемы направление является вполне перспективным и можно ждать развитие этой концепции и популяризацию данной метрики.
Литература
- Herrmannova D., Knoth P. Semantometrics in coauthorship networks: Fulltext-based approach for analysing patterns of research collaboration //D-Lib Magazine. – 2015. – Т. 21. – №. 11/12.
- Herrmannova D., Knoth P., Patton R. Analyzing citation-distance networks for evaluating publication impact. – 2018.
- Kreutz C. K. et al. Evaluating semantometrics from computer science publications //Scientometrics. – 2020. – Т. 125. – №. 3. – С. 2915-2954.
- Herrmannova D., Knoth P. Towards Full-Text Based Research Metrics: Exploring Semantometrics Report of experiments URL http://repository. jisc. ac. uk/6376/1//Jisc-semantometrics- experiments-report-final. pdf. – 2016.

